In-memory distributed processing for large datasets… How to connect to SQL Server using Apache Spark? The Spark documentation covers the basics of the API and Dataframes, there is a lack of info. and examples on actually how to get this feature to work.
![]()

First, what is Apache Spark? Apache Spark is an open source big data processing framework built around speed, ease of use, and sophisticated analytics. A fast and general processing engine compatible with Hadoop data. It can run in Hadoop clusters through YARN or Spark’s standalone mode, and it can process data in HDFS, HBase, Cassandra, Hive, and any Hadoop InputFormat. It is designed to perform both batch processing (similar to MapReduce) and new workloads like streaming, interactive queries, and machine learning.
Spark enables applications in Hadoop clusters to run up to 100 times faster in memory and 10 times faster even when running on disk.
Besides the Spark Core API there are libraries that provide additional capabilities: Spark Streaming, Spark SQL (SQL and Dataframes), Spark MLlib (Machine Learning), Spark GraphX (Graph)
This example will be using Spark SQL which provides the capability to expose the Spark datasets over JDBC API and allow running the SQL like queries on Spark data using BI and visualization tools. Spark SQL allows the users to access their data from different formats it’s currently in (i.e. JSON, Parquet, Database tables), transform it, and expose it for ad-hoc querying.
For the purpose of this demonstration I am connecting remotely to an instance of SQL Server 2016 and have installed the Wide World Importers sample database which you can find and download here -> https://github.com/Microsoft/sql-server-samples/releases/tag/wide-world-importers-v1.0
Most importantly you will need to download and install the latest version of the Microsoft JDBC Drivers for SQL Server located here -> https://www.microsoft.com/en-ca/download/details.aspx?id=11774. Since I am connecting from my Mac I have installed the drivers (4.2) to the following location: /opt/sqljdbc_4.2/enu/sqljdbc42.jar
Open up a Terminal session and issue the following command to start the Spark shell with the Microsoft JDBC Driver
bin/spark-shell --driver-class-path /opt/sqljdbc_4.2/enu/sqljdbc42.jar
The following Scala code snippet demonstrates the Spark SQL commands you can run on the Spark Shell console.
Replace the xxx.xxx.xxx.xxx with your SQL Server Name or IP Address.
I recommend you copy and paste a block of commands at a time to see and understand what is happening…
// Create the SQLContext first from the existing Spark Context
val sqlContext = new org.apache.spark.sql.SQLContext(sc)
// Construct JDBC URL
val jdbcSqlConnStr = "jdbc:sqlserver://xxx.xxx.xxx.xxx;databaseName=WideWorldImporters;user=wwiuser;password=wwiuser1234;"
// Define database table to load into DataFrame
val jdbcDbTable = "Sales.InvoiceLines"
// Load DataFrame with JDBC data-source properties
val jdbcDF = sqlContext.read.format("jdbc").options(
Map("url" -> jdbcSqlConnStr,
"dbtable" -> jdbcDbTable)).load()
// Displays the content of the DataFrame to stdout ...first 10 rows
jdbcDF.show(10)
// Register the DataFrame as a table
jdbcDF.registerTempTable("Sales")
// SQL statement can be run by using the sql methods provided by sqlContext.
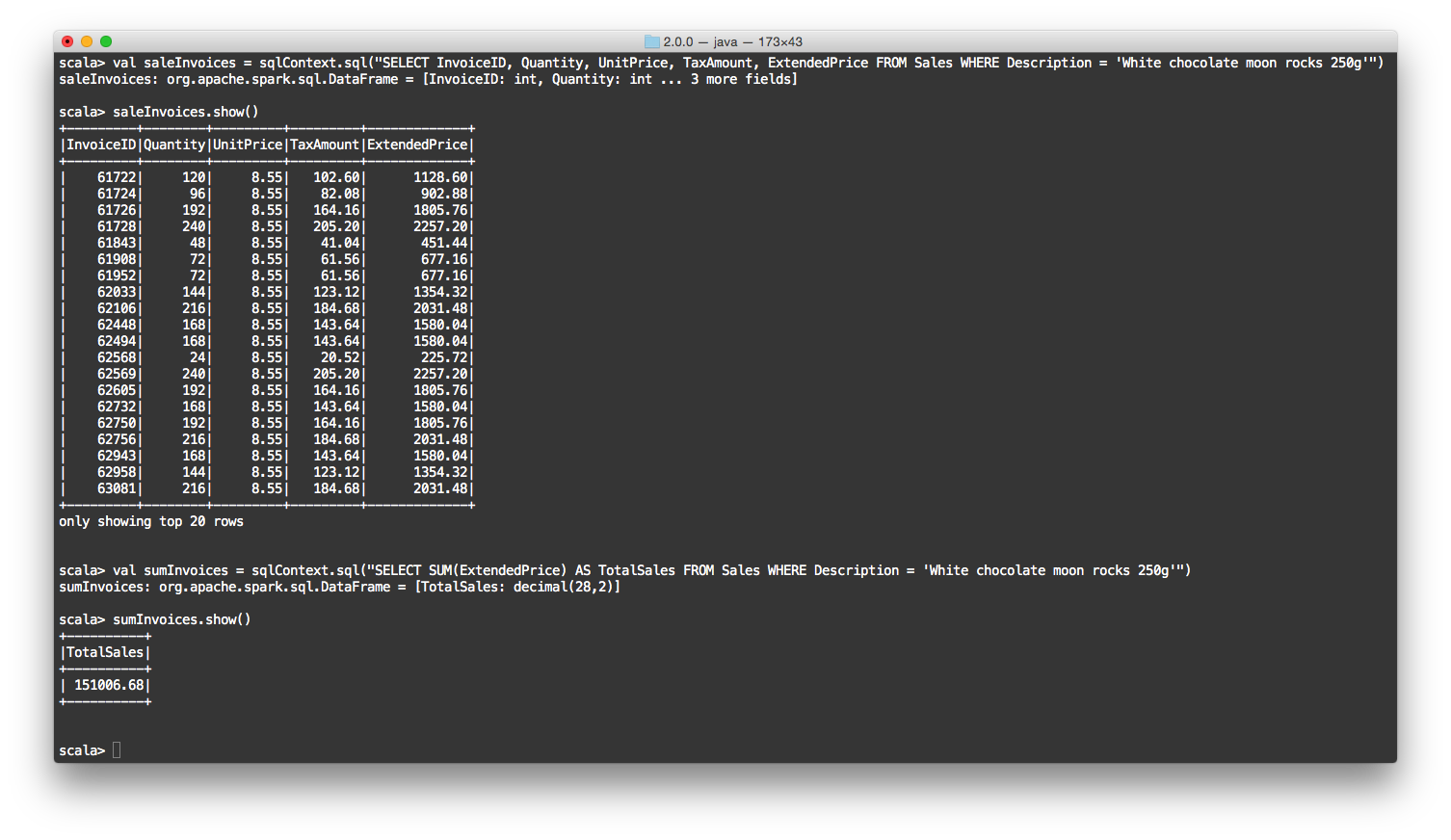
val saleInvoices = sqlContext.sql("SELECT InvoiceID, Quantity, UnitPrice, TaxAmount, ExtendedPrice FROM Sales WHERE Description = 'White chocolate moon rocks 250g'")
// Displays the content of the DataFrame
saleInvoices.show()
//SQL statement - Sum of ExtendedPrice for 'White chocolate moon rocks 250g' product
val sumInvoices = sqlContext.sql("SELECT SUM(ExtendedPrice) AS TotalSales FROM Sales WHERE Description = 'White chocolate moon rocks 250g'")
// Displays the content of the DataFrame
sumInvoices.show()
Sample Terminal output…
In this post, we quickly looked at how Apache Spark SQL works to provide an SQL interface to SQL Server and interact with Spark data using the familiar SQL query syntax.