Graphs are everywhere! In my efforts to spread the word and inform SQL Server Professionals about Neo4j and learn how to take a relational database schema and model it as a graph… AdventureWorks was a no-brainer! Let’s explore how to import a subset of the AdventureWorks database from SQL Server (RDBMS) into Neo4j (GraphDB).
But first some prerequisites. You should at least have a basic understanding of what is a property graph model and have completed the following modeling guidelines. Download and install Neo4j to be able to follow along with the examples.
The AdventureWorks database is a fictitious company database that has existed since SQL Server 2005 as a means to show new functionality in each new version released. AdventureWorks has become a vital aspect of learning new features/constructs within SQL Server.
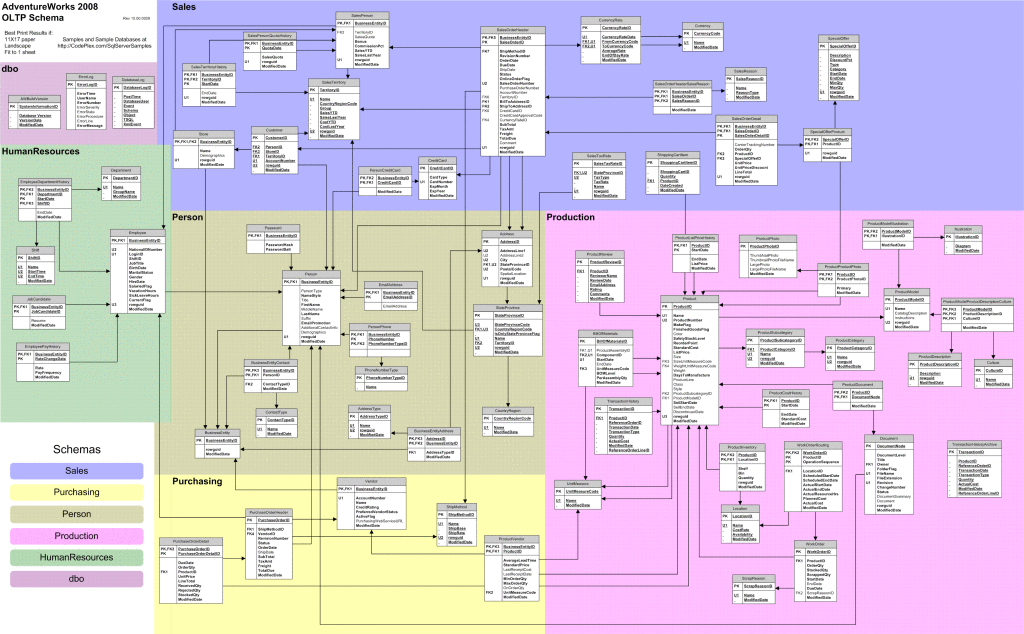
For our demonstration I have decided to choose a subset of tables and select only offline sales transactions (OnlineOrderFlag = 0).
As a result the following CSV files will be used to import data into our graph structure:
- customers.csv
- employees.csv
- orders.csv
- productcategories.csv
- products.csv
- producsubcategories.csv
- vendorproduct.csv
- vendors.csv You can find all the necessary code and files here -> https://github.com/sfrechette/adventureworks-neo4j
If you still need to download a copy of the AdventureWorks sample database (I used the SQL Server 2014 version) you can find them here -> https://msftdbprodsamples.codeplex.com/
Developing a Graph Model
When deriving and defining a graph model from a relational model, you should keep the following base guidelines in mind:
- A row is a node
- A table name is a label name For further understanding read the following GraphDB vs. RDBMS. This article explores the differences between relational and graph databases and data models. In addition, it explains how to integrate graph databases with relational databases and how to import data from a relational store.
With this dataset, this simple AdventureWorks graph data model serves as a foundation:
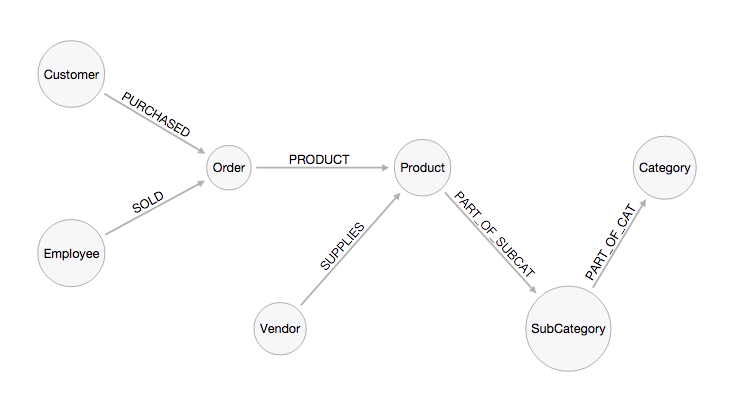
The key difference between a graph and relational database is that relational databases work with sets while graph databases work with paths and relationships are first-class entities in a graph database and are semantically far stronger than those implied relationships reified at runtime in a relational store.
Importing the Data using Cypher
Now that we have extracted data from the AdventureWorks database, will be using Cypher’s LOAD CSV command to transform and load the content of these CSV files into a graph structure.
First we create specific indexes and constraints
// Create indexes for faster lookup
CREATE INDEX ON :Category(categoryName);
CREATE INDEX ON :SubCategory(subCategoryName);
CREATE INDEX ON :Vendor(vendorName);
CREATE INDEX ON :Product(productName);
// Create constraints
CREATE CONSTRAINT ON (o:Order) ASSERT o.orderId IS UNIQUE;
CREATE CONSTRAINT ON (p:Product) ASSERT p.productId IS UNIQUE;
CREATE CONSTRAINT ON (c:Category) ASSERT c.categoryId IS UNIQUE;
CREATE CONSTRAINT ON (s:SubCategory) ASSERT s.subCategoryId IS UNIQUE;
CREATE CONSTRAINT ON (e:Employee) ASSERT e.employeeId IS UNIQUE;
CREATE CONSTRAINT ON (v:Vendor) ASSERT v.vendorId IS UNIQUE;
CREATE CONSTRAINT ON (c:Customer) ASSERT c.customerId IS UNIQUE;
Schema await – now create nodes:
// Create products
USING PERIODIC COMMIT
LOAD CSV WITH HEADERS FROM "file:data/products.csv" as row
CREATE (:Product {productName: row.ProductName, productNumber: row.ProductNumber, productId: row.ProductID, modelName: row.ProductModelName, standardCost: row.StandardCost, listPrice: row.ListPrice});
// Create vendors
USING PERIODIC COMMIT
LOAD CSV WITH HEADERS FROM "file:data/vendors.csv" as row
CREATE (:Vendor {vendorName: row.VendorName, vendorNumber: row.AccountNumber, vendorId: row.VendorID, creditRating: row.CreditRating, activeFlag: row.ActiveFlag});
// Create employees
USING PERIODIC COMMIT
LOAD CSV WITH HEADERS FROM "file:data/employees.csv" as row
CREATE (:Employee {firstName: row.FirstName, lastName: row.LastName, fullName: row.FullName, employeeId: row.EmployeeID, jobTitle: row.JobTitle, organizationLevel: row.OrganizationLevel, maritalStatus: row.MaritalStatus, gender: row.Gender, territoty: row.Territory, country: row.Country, group: row.Group});
// Create customers
USING PERIODIC COMMIT
LOAD CSV WITH HEADERS FROM "file:data/customers.csv" as row
CREATE (:Customer {firstName: row.FirstName, lastName: row.LastName, fullName: row.FullName, customerId: row.CustomerID});
// Create categories
USING PERIODIC COMMIT
LOAD CSV WITH HEADERS FROM "file:data/productcategories.csv" as row
CREATE (:Category {categoryName: row.CategoryName, categoryId: row.CategoryID});
// Create sub-categories
USING PERIODIC COMMIT
LOAD CSV WITH HEADERS FROM "file:data/productsubcategories.csv" as row
CREATE (:SubCategory {subCategoryName: row.SubCategoryName, subCategoryId: row.SubCategoryID});
// Prepare orders
USING PERIODIC COMMIT
LOAD CSV WITH HEADERS FROM "file:data/orders.csv" AS row
MERGE (order:Order {orderId: row.SalesOrderID}) ON CREATE SET order.orderDate = row.OrderDate;
Create relationships
// Create relationships: Order to Product
USING PERIODIC COMMIT
LOAD CSV WITH HEADERS FROM "file:data/orders.csv" AS row
MATCH (order:Order {orderId: row.SalesOrderID})
MATCH (product:Product {productId: row.ProductID})
MERGE (order)-[pu:PRODUCT]->(product)
ON CREATE SET pu.unitPrice = toFloat(row.UnitPrice), pu.quantity = toFloat(row.OrderQty);
// Create relationships: Order to Employee
USING PERIODIC COMMIT
LOAD CSV WITH HEADERS FROM "file:data/orders.csv" AS row
MATCH (order:Order {orderId: row.SalesOrderID})
MATCH (employee:Employee {employeeId: row.EmployeeID})
MERGE (employee)-[:SOLD]->(order);
// Create relationships: Order to Customer
USING PERIODIC COMMIT
LOAD CSV WITH HEADERS FROM "file:data/orders.csv" AS row
MATCH (order:Order {orderId: row.SalesOrderID})
MATCH (customer:Customer {customerId: row.CustomerID})
MERGE (customer)-[:PURCHASED]->(order);
// Create relationships: Product to Vendor
USING PERIODIC COMMIT
LOAD CSV WITH HEADERS FROM "file:data/vendorproduct.csv" AS row
MATCH (product:Product {productId: row.ProductID})
MATCH (vendor:Vendor {vendorId: row.VendorID})
MERGE (vendor)-[:SUPPLIES]->(product);
// Create relationships: Product to SubCategory
USING PERIODIC COMMIT
LOAD CSV WITH HEADERS FROM "file:data/products.csv" AS row
MATCH (product:Product {productId: row.ProductID})
MATCH (subcategory:SubCategory {subCategoryId: row.SubCategoryID})
MERGE (product)-[:PART_OF_SUBCAT]->(subcategory);
// Create relationships: SubCategory to Category
USING PERIODIC COMMIT
LOAD CSV WITH HEADERS FROM "file:data/productsubcategories.csv" AS row
MATCH (subcategory:SubCategory {subCategoryId: row.SubCategoryID})
MATCH (category:Category {categoryId: row.CategoryID})
MERGE (subcategory)-[:PART_OF_CAT]->(category);
// Create relationship for employee reporting structure
USING PERIODIC COMMIT
LOAD CSV WITH HEADERS FROM "file:data/employees.csv" AS row
MATCH (employee:Employee {employeeId: row.EmployeeID})
MATCH (manager:Employee {employeeId: row.ManagerID})
MERGE (employee)-[:REPORTS_TO]->(manager);
You can also import and run the entire Cypher script using the neo4j-shell: bin/neo4j-shell -path adventure.db -file cypher/import.cypher
Once completed you will be able query and do stuff like this:
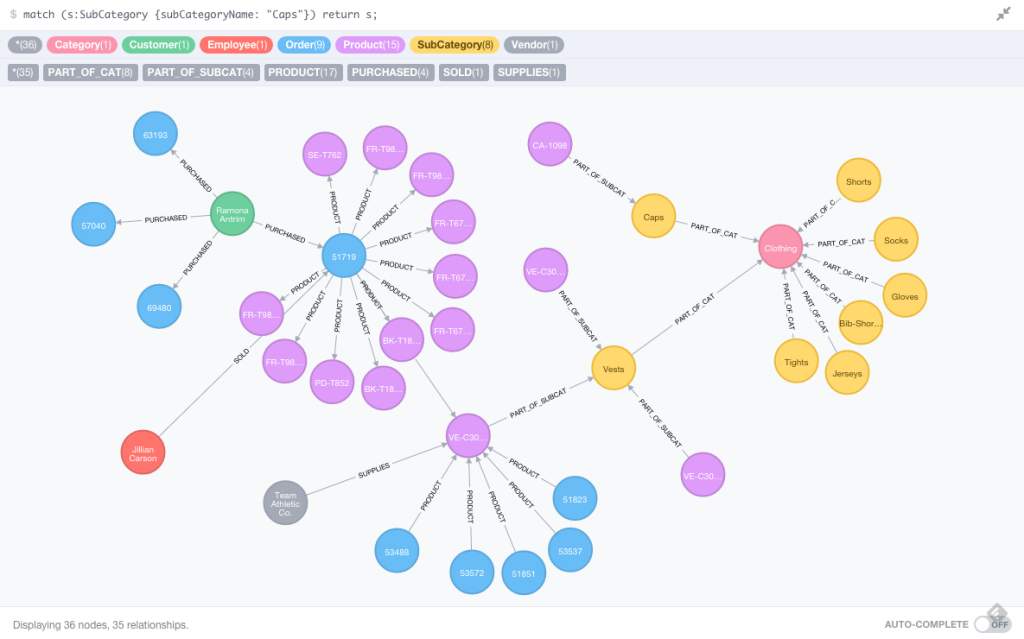
Querying the Graph with Cypher
Let’s issue some cypher queries to our newly created graph database:
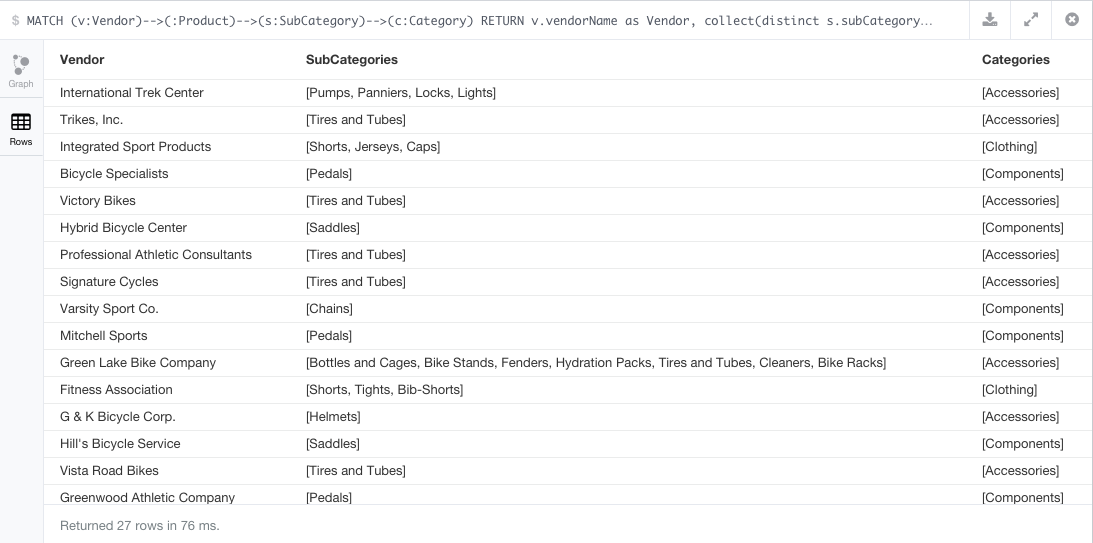
// List the product subcategories and categories provided by each supplier.
MATCH (v:Vendor)-->(:Product)-->(s:SubCategory)-->(c:Category)
RETURN v.vendorName as Vendor, collect(distinct s.subCategoryName) as SubCategories, collect(distinct c.categoryName) as Categories;
// Which employee had the highest cross-selling count of 'AWC Logo Cap' and which product?
MATCH (p:Product {productName:'AWC Logo Cap'})< -[:PRODUCT]-(:Order)<-[:SOLD]-(employee),
(employee)-[:SOLD]->(o2)-[:PRODUCT]->(other:Product)
RETURN employee.fullName as Employee, other.productName as Product, count(distinct o2) as Count
ORDER BY Count DESC
LIMIT 5;
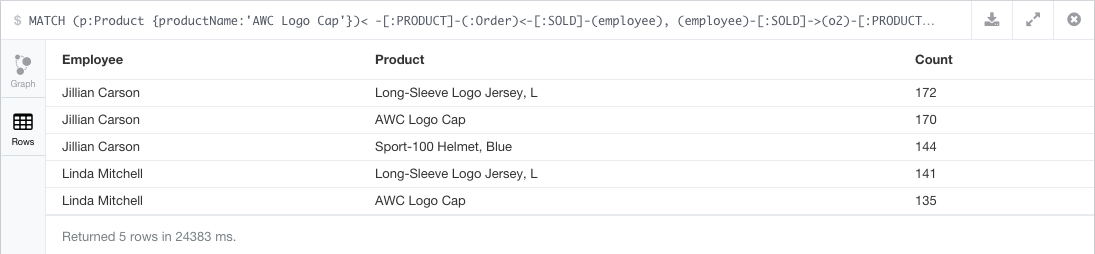
// What is the total quantity sold of a particular product?
MATCH (o:Order)-[r:PRODUCT]->(p:Product {productName: "Long-Sleeve Logo Jersey, L"})
RETURN sum(r.quantity) as TotalQuantitySold;
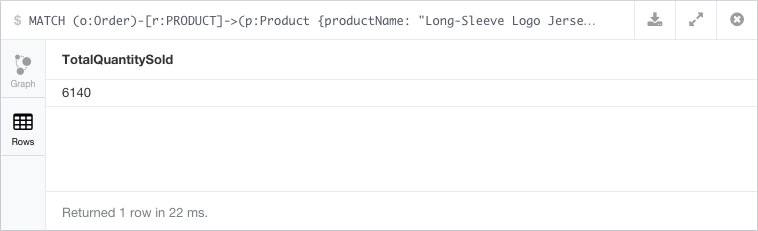
Explore, learn Cypher and write your own queries
Enjoy!