
How to get started with Cloud Data Fusion? This post shows you how to simply build and use the Wrangler and Data Pipelines features in Cloud Data Fusion to clean, transform and process flight data.
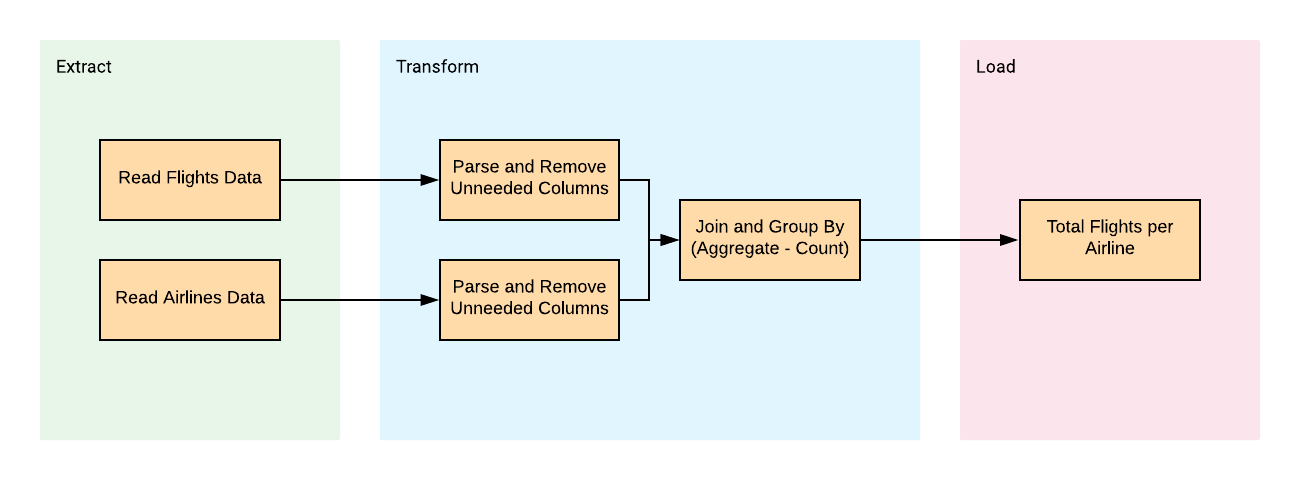
ETL Process
The diagram shows the transformations which are going to take place. This will be to read the two files, transform the data and loading it into one output; Total Flights per Airline.
Objectives Link to heading
- Connect Cloud Data Fusion to data sources
- Apply basic transformations
- Join and Group By data sources
- Write to a sink
You are ready to begin!
Log on to the GCP Console Link to heading
First go to the GCP console and log in using your Google account.
Select or Create a GCP project Link to heading
You need to select a project. If you don’t have any projects then go to the project selector page to create one - For this exercise I have created and using a specific project named flights-analysis. I highly recommend you create a new project for this walkthrough. Refer to Creating your project if you need assistance.
Create GCS bucket and copy data Link to heading
You need data! The two small datasets are located in a GCS bucket that you will need to copy to your own bucket.
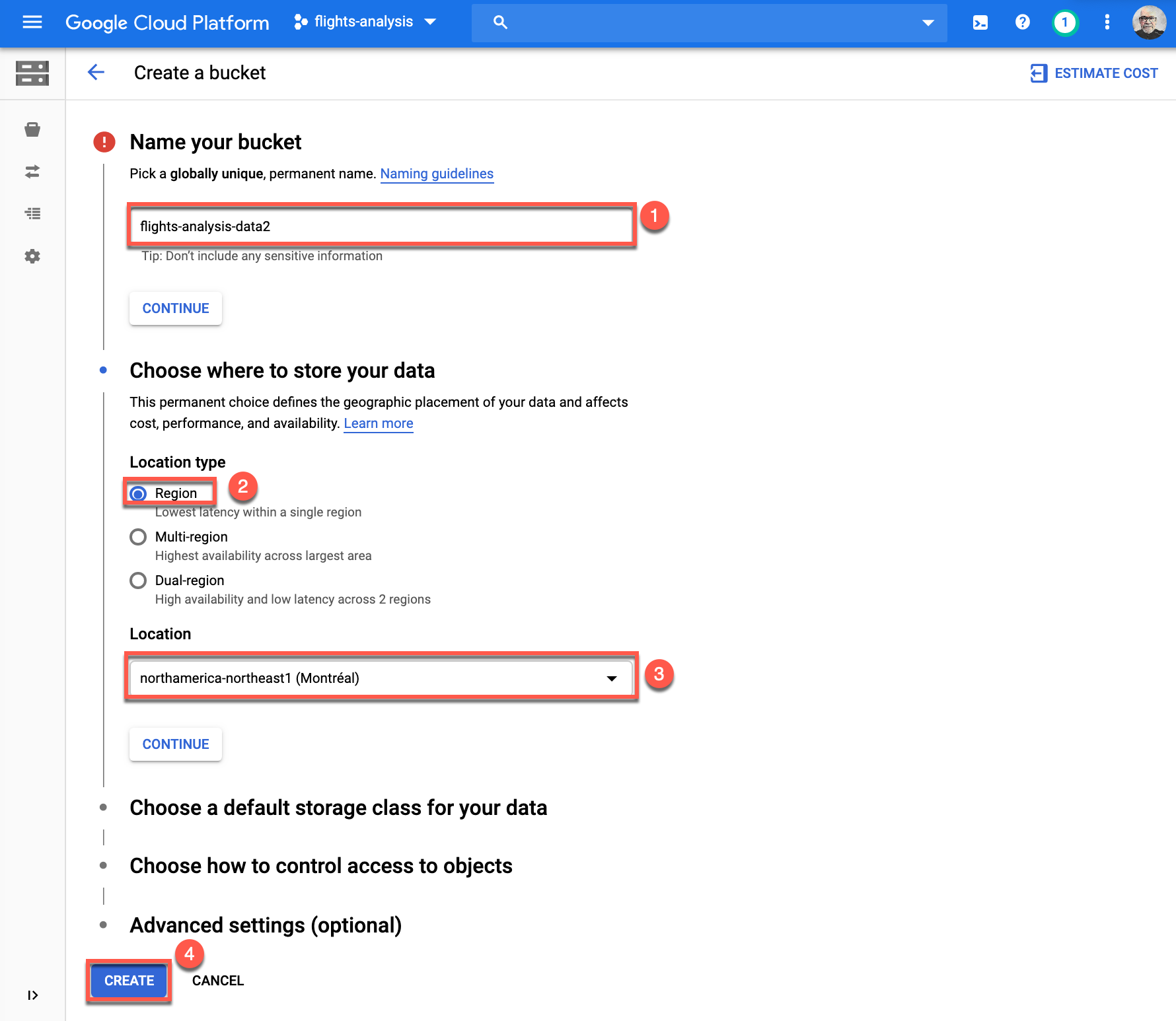
First create your bucket, you can do this by typing bucket in the resources and products search field and select Create bucket.

Once on the Create a bucket page, provide the name of your bucket (1), keep in mind that these are globally unique and for the purpose of demonstration I have inputted flights-analysis-data2. Choose Region (2) for Location type and select your desired Location (3), I have chosen northamerica-northeast1 for demonstration, then click Create (4) to create your bucket.
Activate Cloud Shell
You now need to Active Cloud Shell, In GCP console, on the top right toolbar, click the Open Cloud Shell button. You can click Continue immediately when the dialog box opens.

It takes a few moments to provision and connect to the environment. When you are connected, you are already authenticated, and the project is set to your PROJECT_ID.
The output is similar to the following:

You need to issue the following commands to copy the required sample files and structure to your GCS bucket. Replace [BUCKET_NAME] with the name of the bucket you created earlier.
gsutil cp gs://flights-analysis-sample-data/input/airlines.csv gs://[BUCKET_NAME]]/input/
gsutil cp gs://flights-analysis-sample-data/input/flights_small.csv gs://[BUCKET_NAME]/input/
The output is similar to the following:

Create a Cloud Data Fusion instance Link to heading
You are now ready to create your Cloud Data Fusion instance.
-
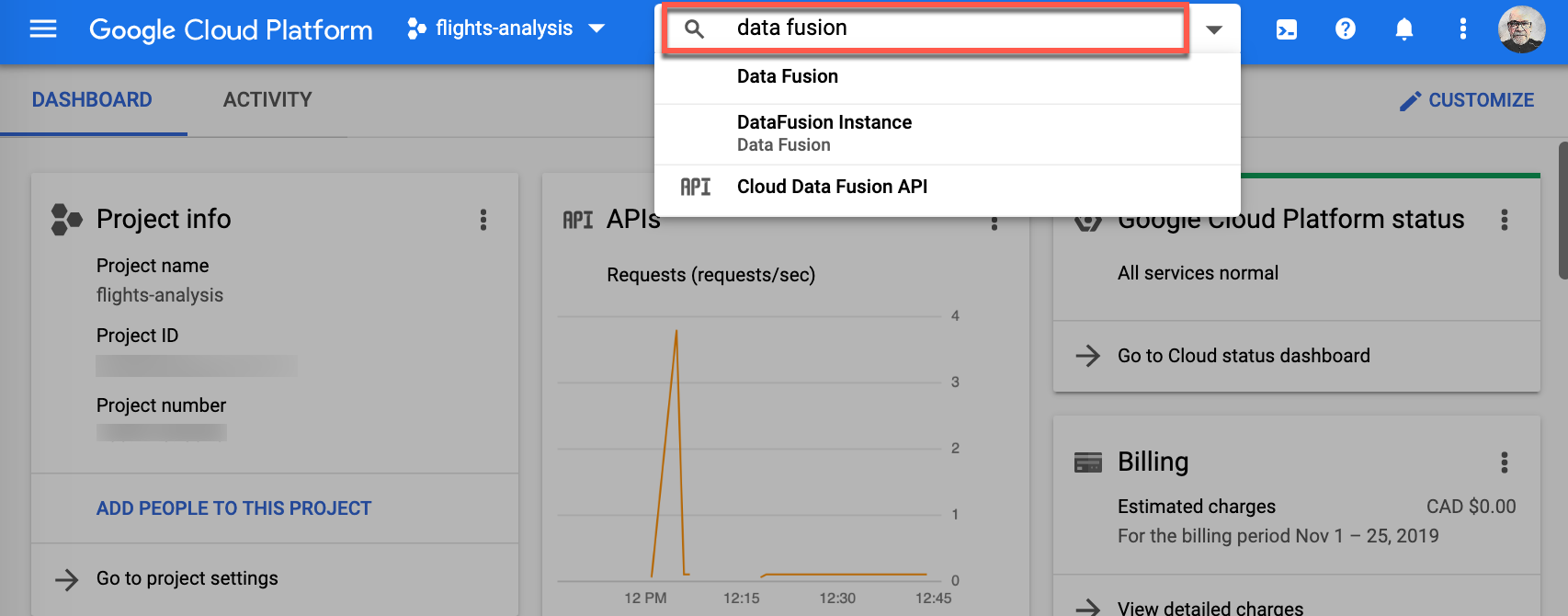
Go to the Cloud Data Fusion page, you can do this by typing data fusion in the resources and products search field and select Data Fusion.
-
If the Cloud Data Fusion API is not already enabled, you will have to enable it by clicking Enable.
This might take a while to complete.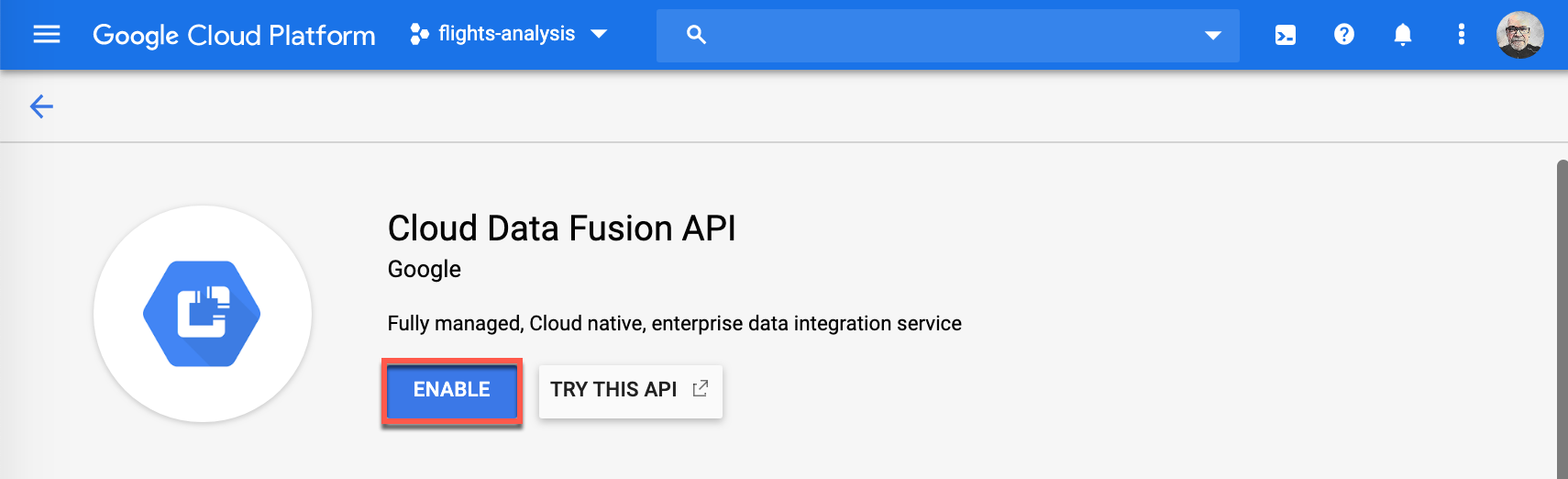
-
Make your way back to the Data Fusion page, you are now ready to create a Data Fusion instance, click Create An Instance.
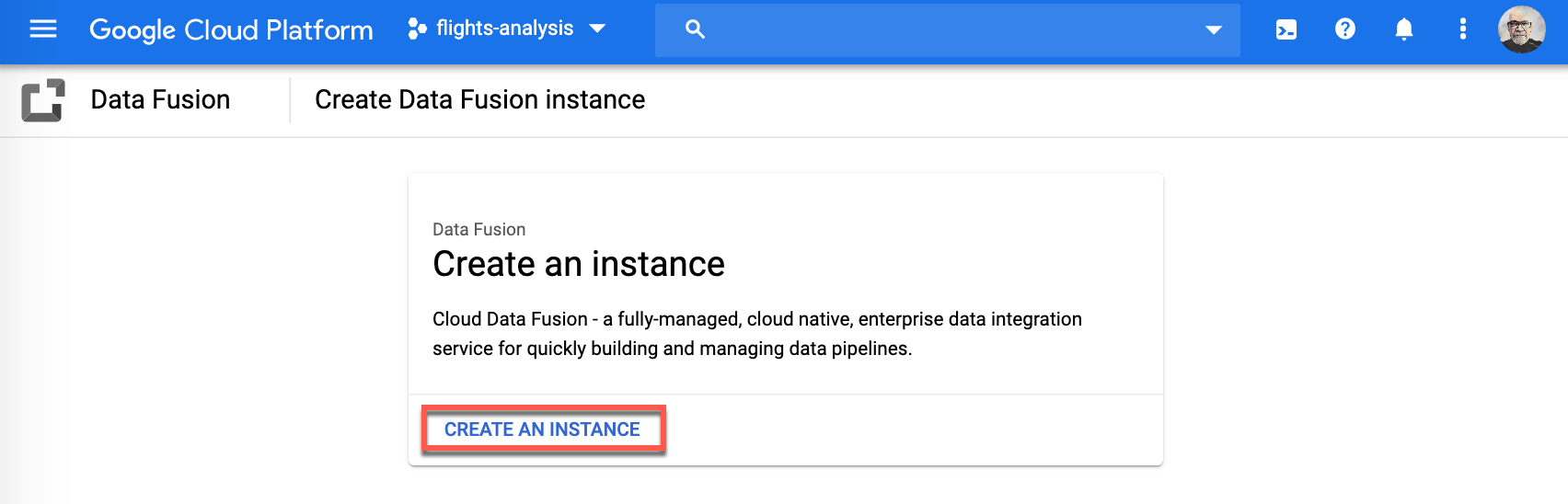
-
Provide an Instance name (1), select your Region (2), select Basic for Edition (3), and click Create (4) to deploy your instance. For the purpose of this exercise I have chosen flights_data-etl for the name of my instance and chosen northamerica-northeast1 as my region. You can supply your own values for these properties.
Note: This will take several minutes to complete (be patient).
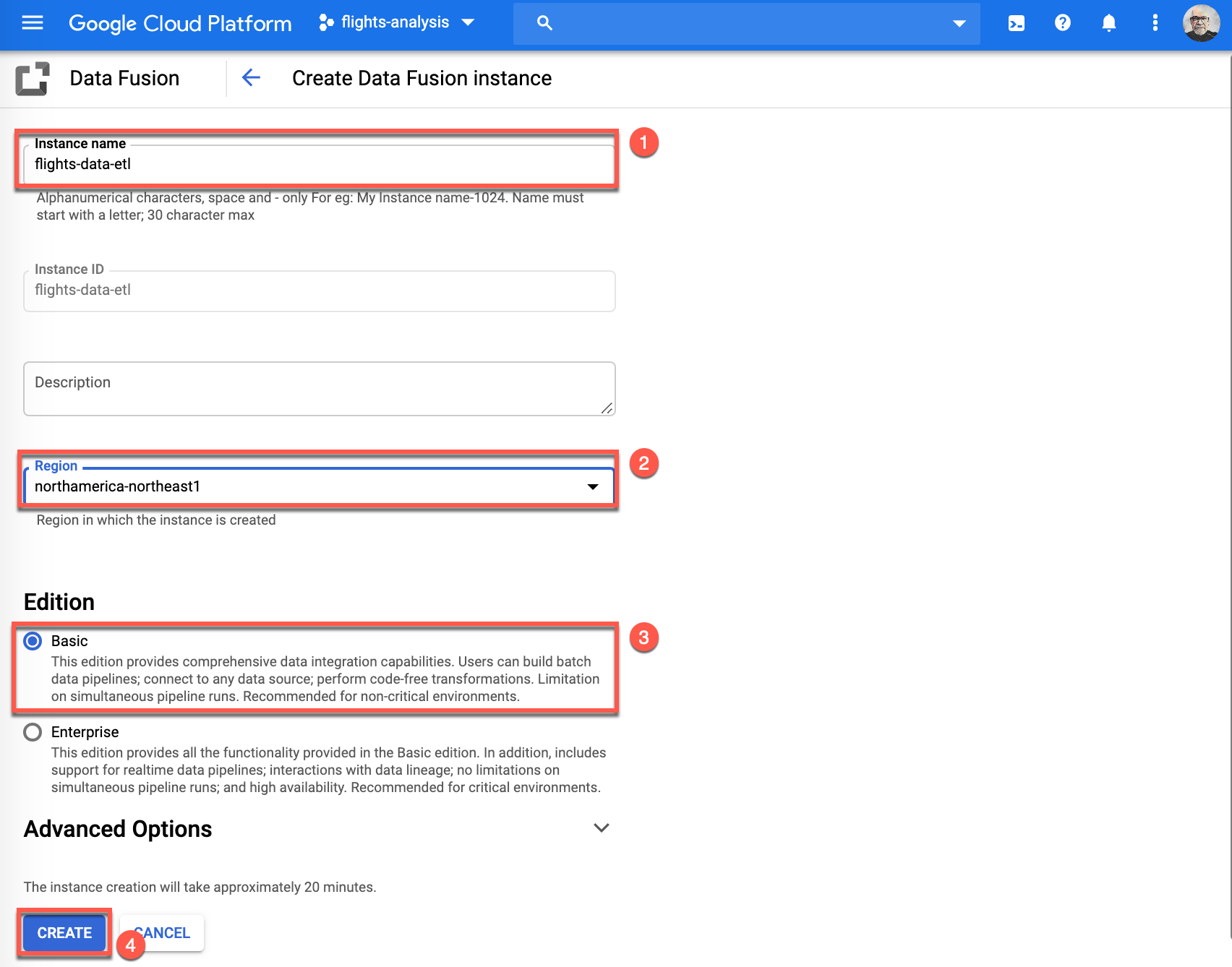
-
Once the instance has deployed successfully, you will see a green check mark, click View Instance to continue.
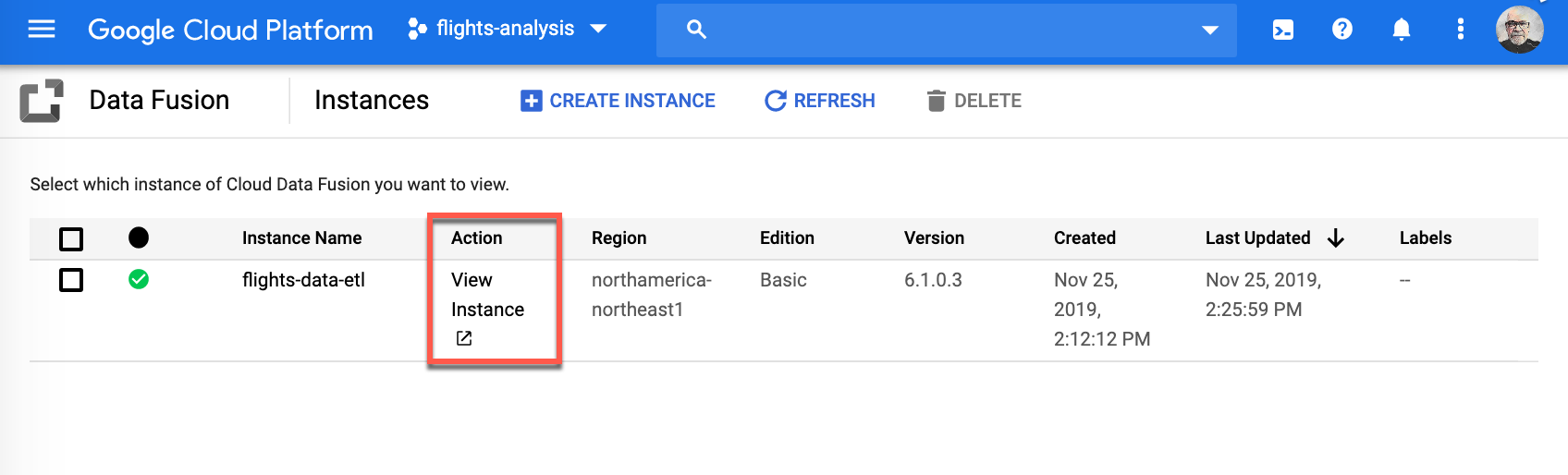
-
The next page provides an overview of properties for your instance, please click View instance to go to your Cloud Data Fusion instance.
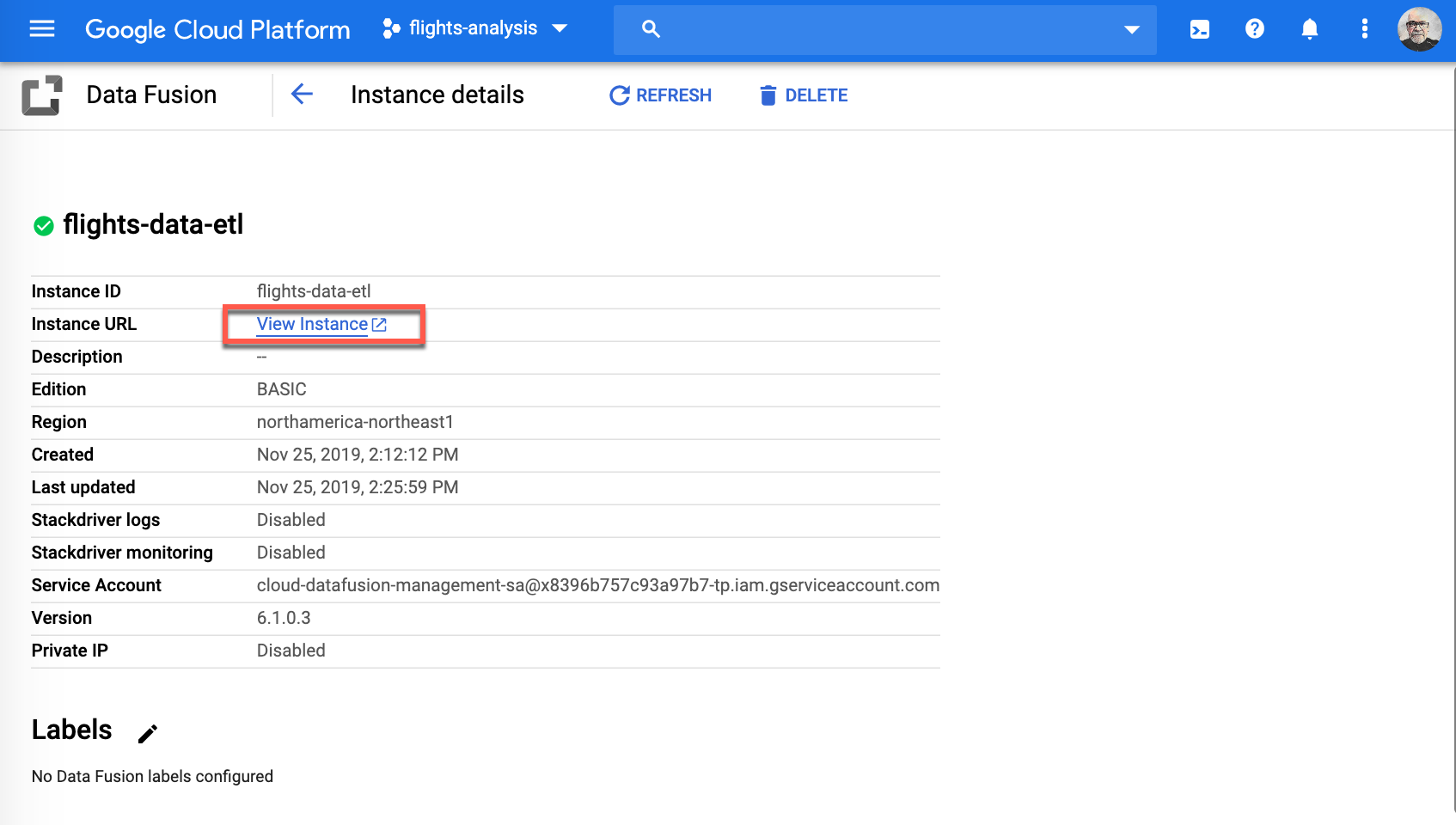
-
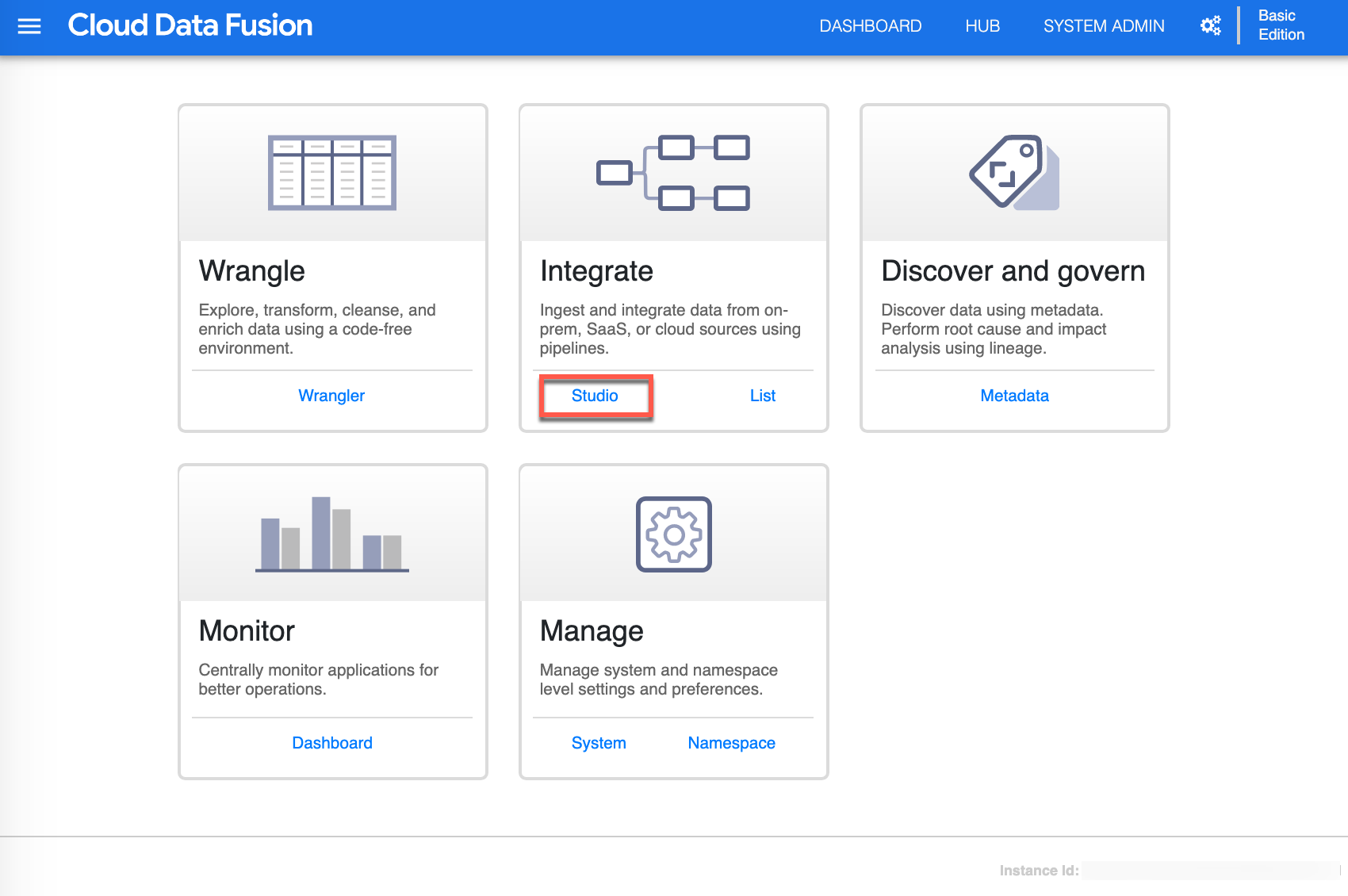
Great work! You are now in your Cloud Data Fusion instance. Since you will be designing your data pipeline click Studio to continue.
Building the data pipeline Link to heading
-
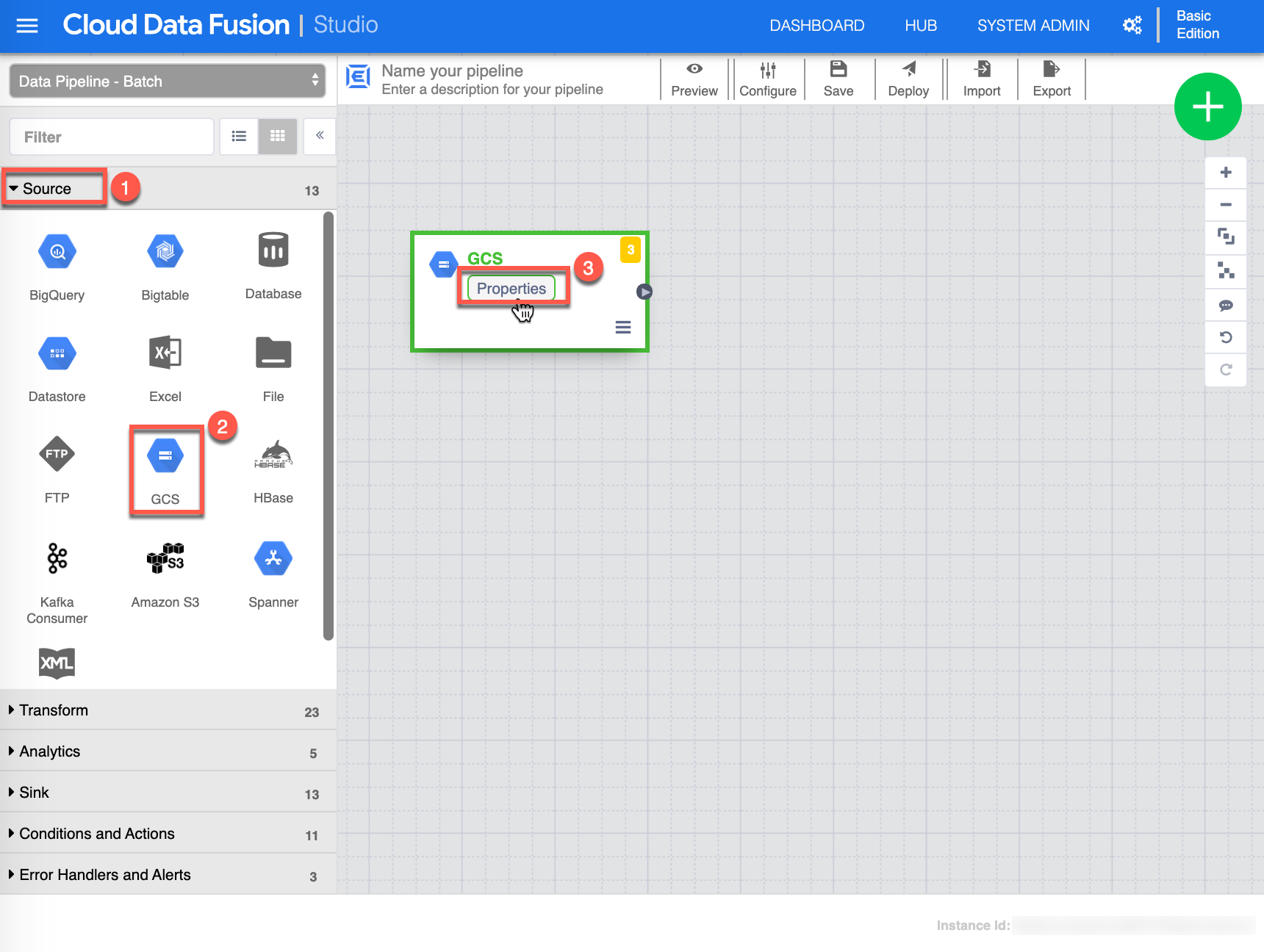
Once in the Studio canvas, you are now ready to build the data pipeline. Start by selecting or make sure you are in Source (1) view , click GCS (2) source - this will add a GCS source on the canvas, then click Properties (3) from the GCS Source to continue.
-
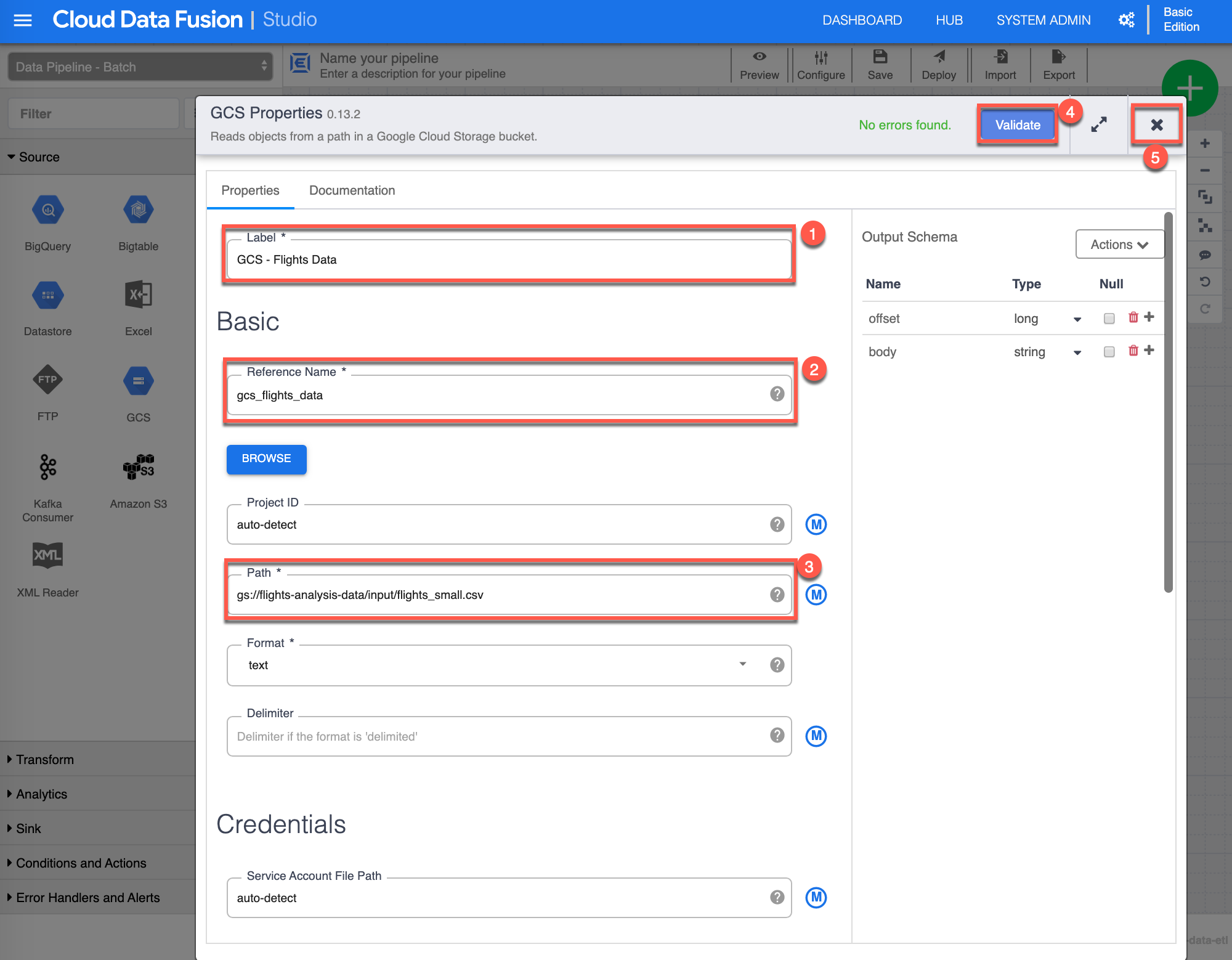
The GCS Properties configuration page shows up. Assign the following value for Label (1): “GCS - Flights Data”, then input the following value for Reference Name (2): “gcs_flights_data”, provide the Path (3) to the GCS Bucket you have created earlier, where you have stored the flight_small.csv file. For the purpose of this exercise I have include mine, make sure to supply your appropriate path (if you input what is provided in this image, the validation won’t succeed). Click Validate (4) to validate all properties, you should see in green No errors found, finally click X (5) to close/save the GSC properties.
-
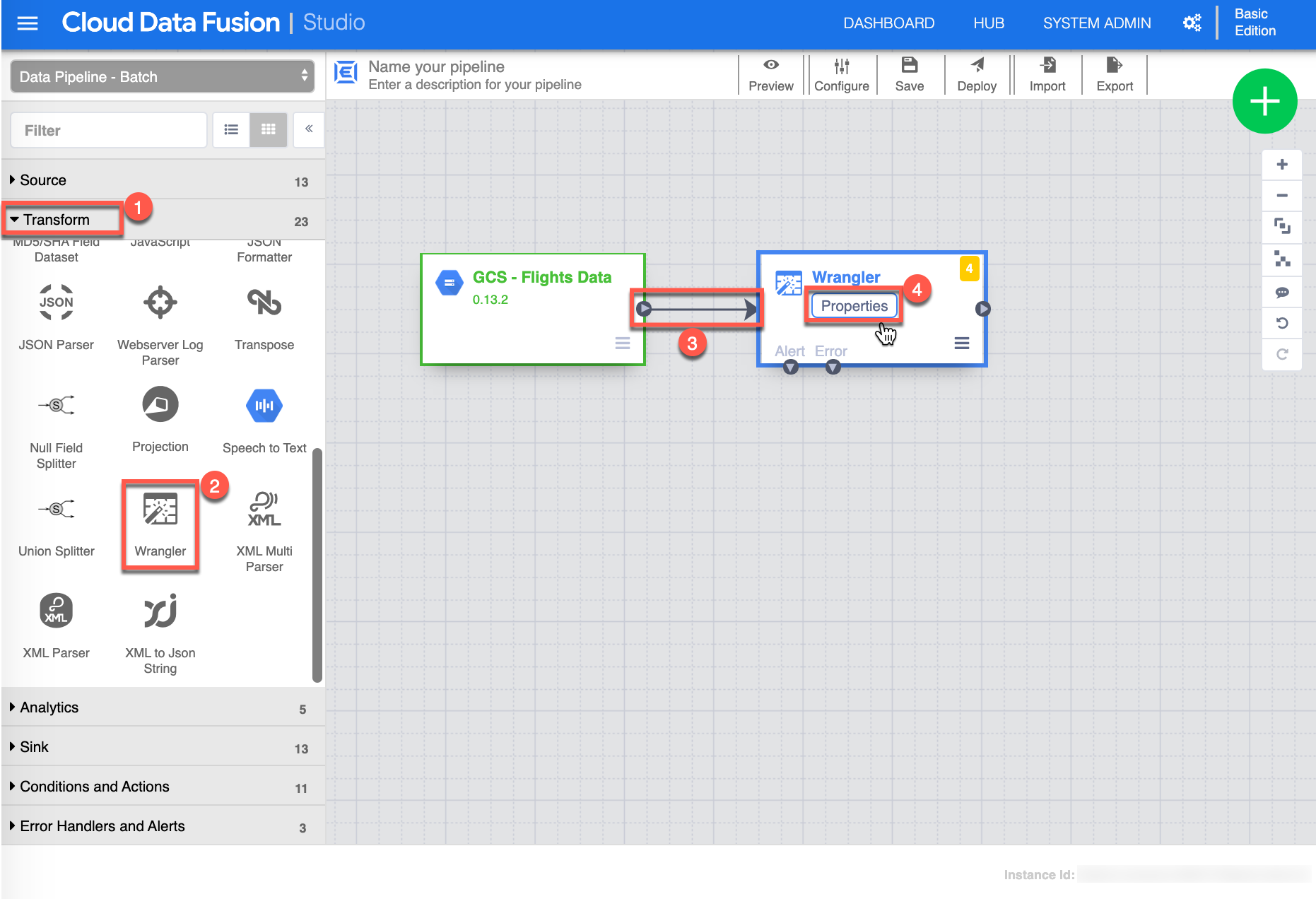
Next step is to Wrangle the flights_small.csv dataset, select or make sure you are in Transform (1) view, click the Wrangler (2) transform - this will add a Wrangler transform on the canvas, then Connect (3) by choosing and dragging the small arrow from the GCS - Flights Data source to the Wrangler transform and click Properties (4) from the Wrangler transform to continue.
-
The Wrangler Properties configuration page shows up. Assign the following value for Label (1): “Wrangler - Flights Data”, then click Wrangle (2) to continue.
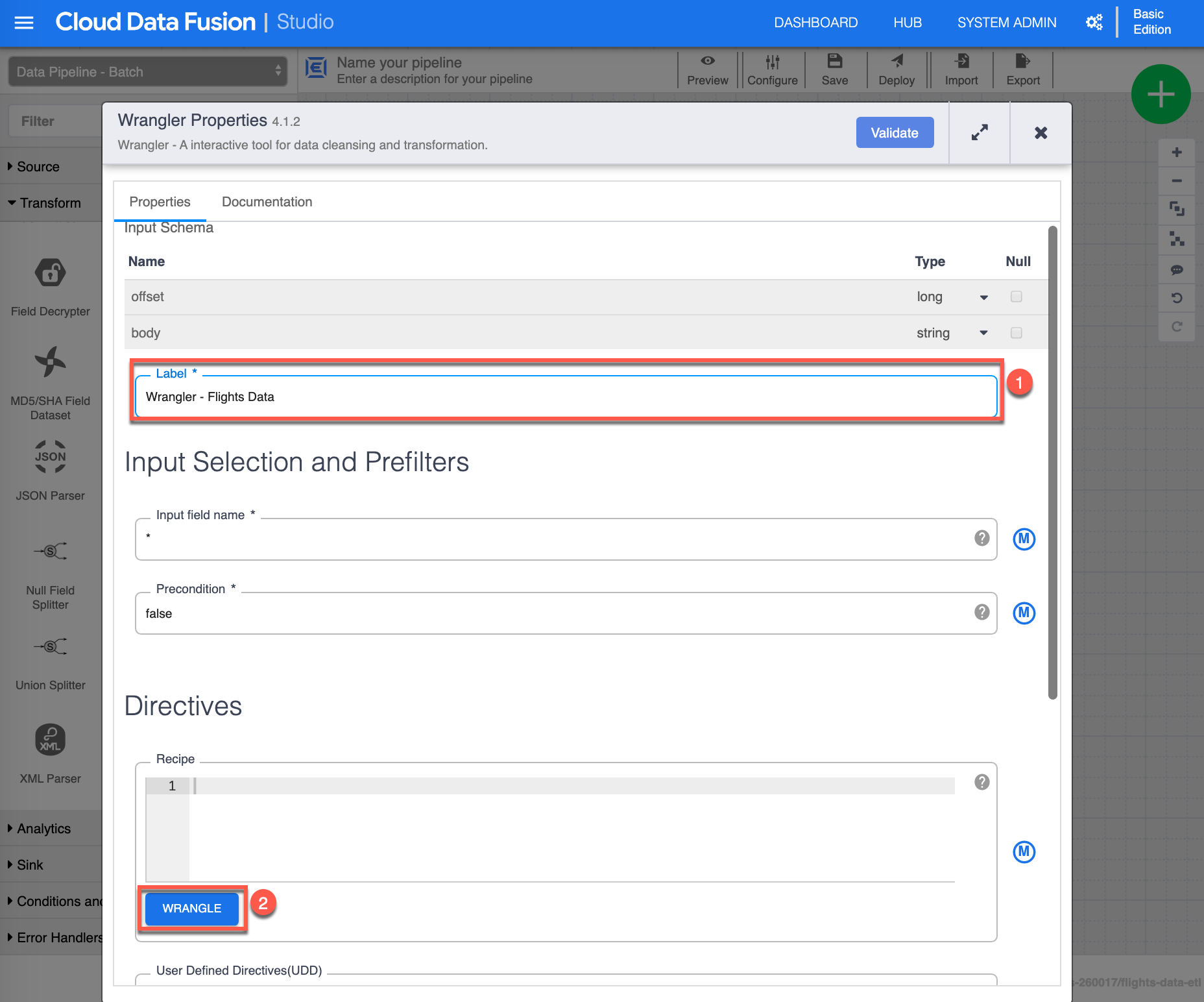
-
You will need to select/load data, choose the flights_small.csv file that is located in your GCS bucket you created earlier to continue.
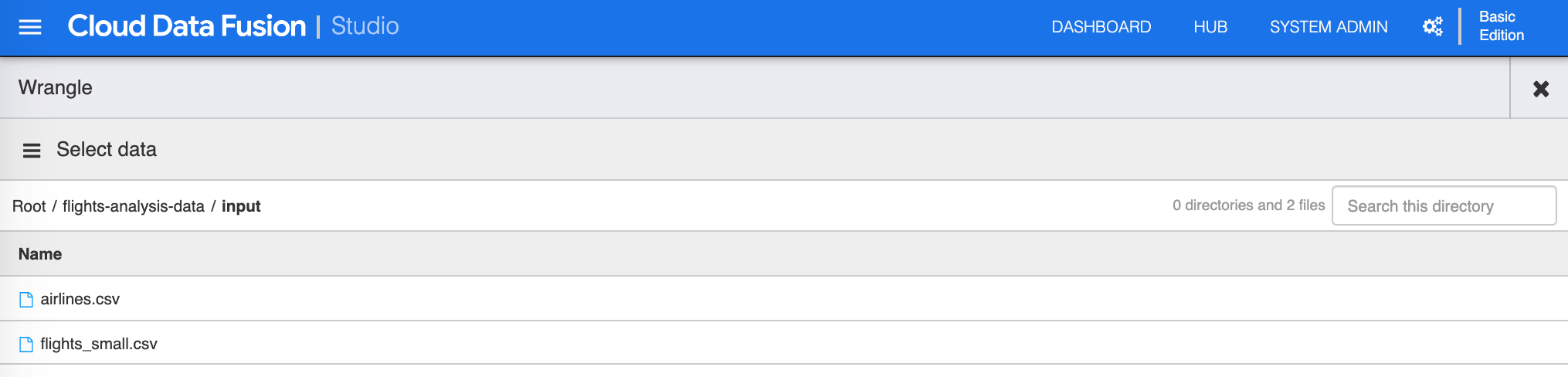
-
Next are a series of steps to parse and remove unwanted columns. Click the dropdown [Column transformations] on the body (1) column, select Parse -> CSV (2), select Comma (3) as the delimiter, check Set first row as header (4), then click Apply (5) to continue.
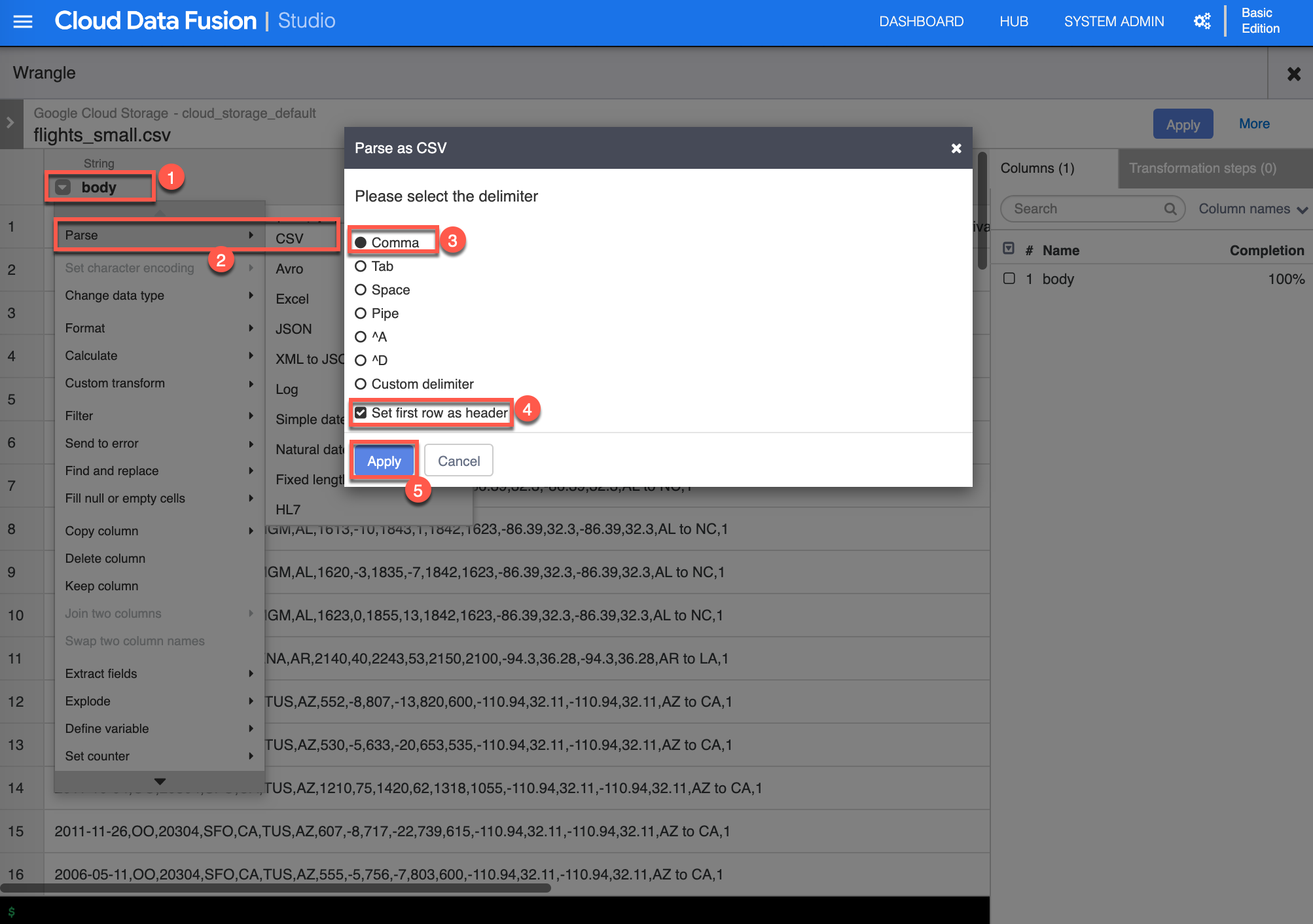
-
The result of the parse column transform added new columns that we need to remove. Select the following columns (1), click the dropdown [Column transformations] on the body (2) column, then select Delete selected columns (3) to continue.
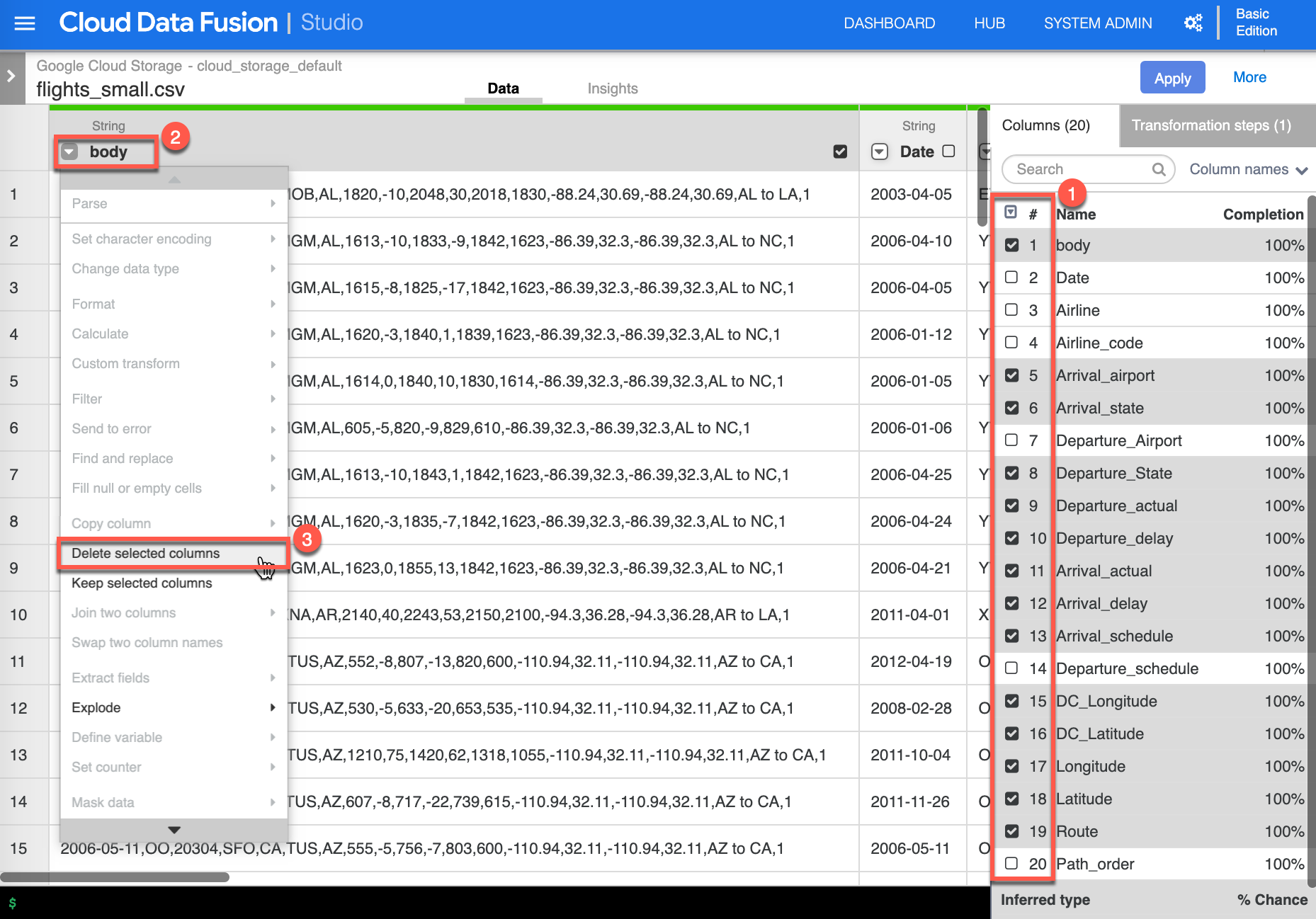
-
The result now show only the columns that you need to move forward. Click Apply to confirm and continue.
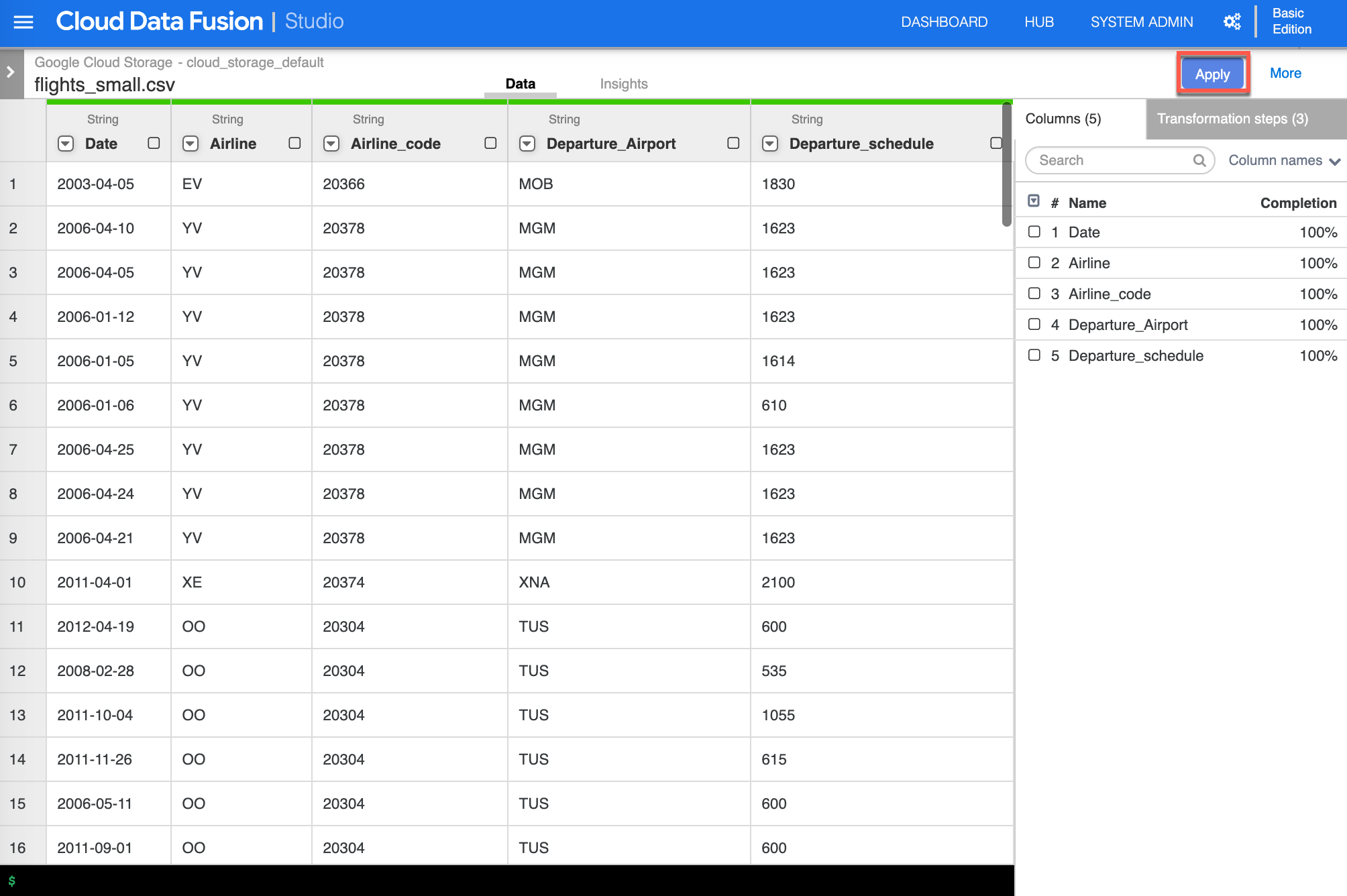
-
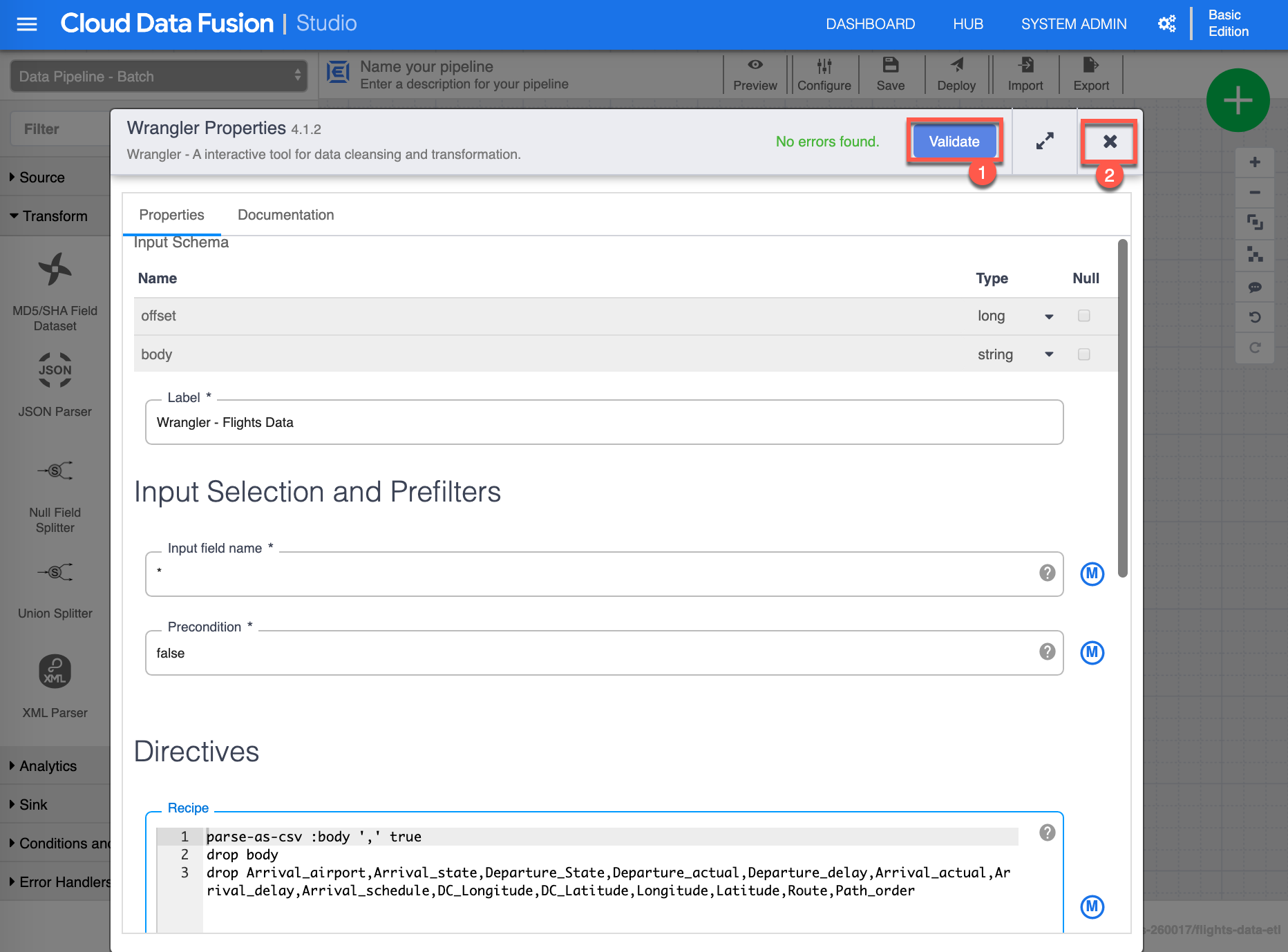
You will now notice that the Recipe box as been populated with the directives you just did in the Wrangling activities. Click Validate (1) to validate all properties, you should see in green No errors found, finally click X (2) to close/save the Wrangler properties.
-
Now let’s add the arlines.csv dataset. Start by selecting or make sure you are in Source (1) view , click GCS (2) source - this will add an other GCS source on the canvas, then click Properties (3) from the GCS Source to continue.
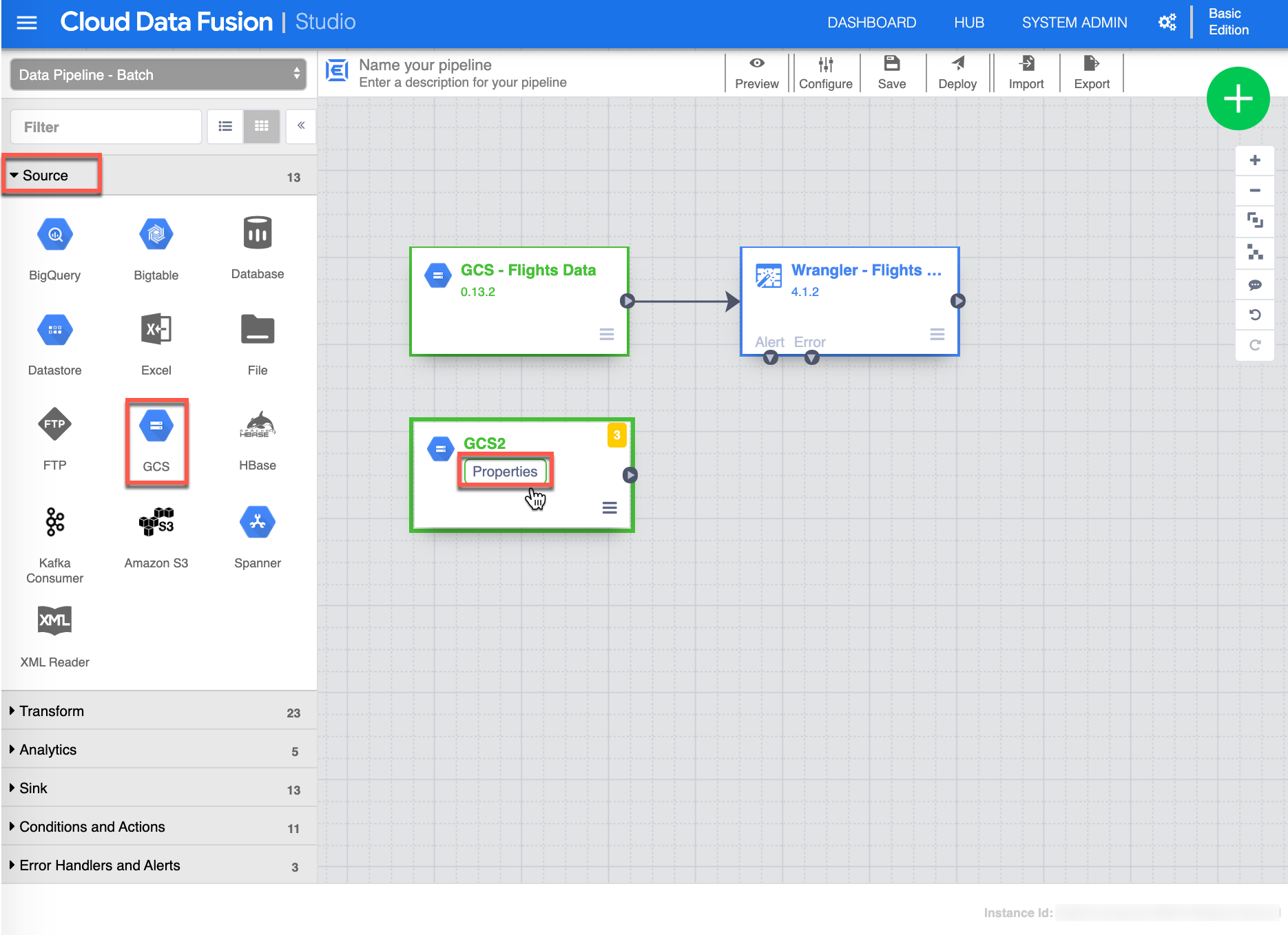
-
The GCS Properties configuration page shows up. Assign the following value for Label (1): “GCS - Airlines Data”, then input the following value for Reference Name (2): “gcs_airlines_data”, provide the Path (3) to the GCS Bucket you have created earlier, where you have stored the airlines.csv file. For the purpose of this exercise I have include mine, make sure to supply your appropriate path (if you input what is provided in this image, the validation won’t succeed). Click Validate (4) to validate all properties, you should see in green No errors found, finally click X (5) to close/save the GSC properties.
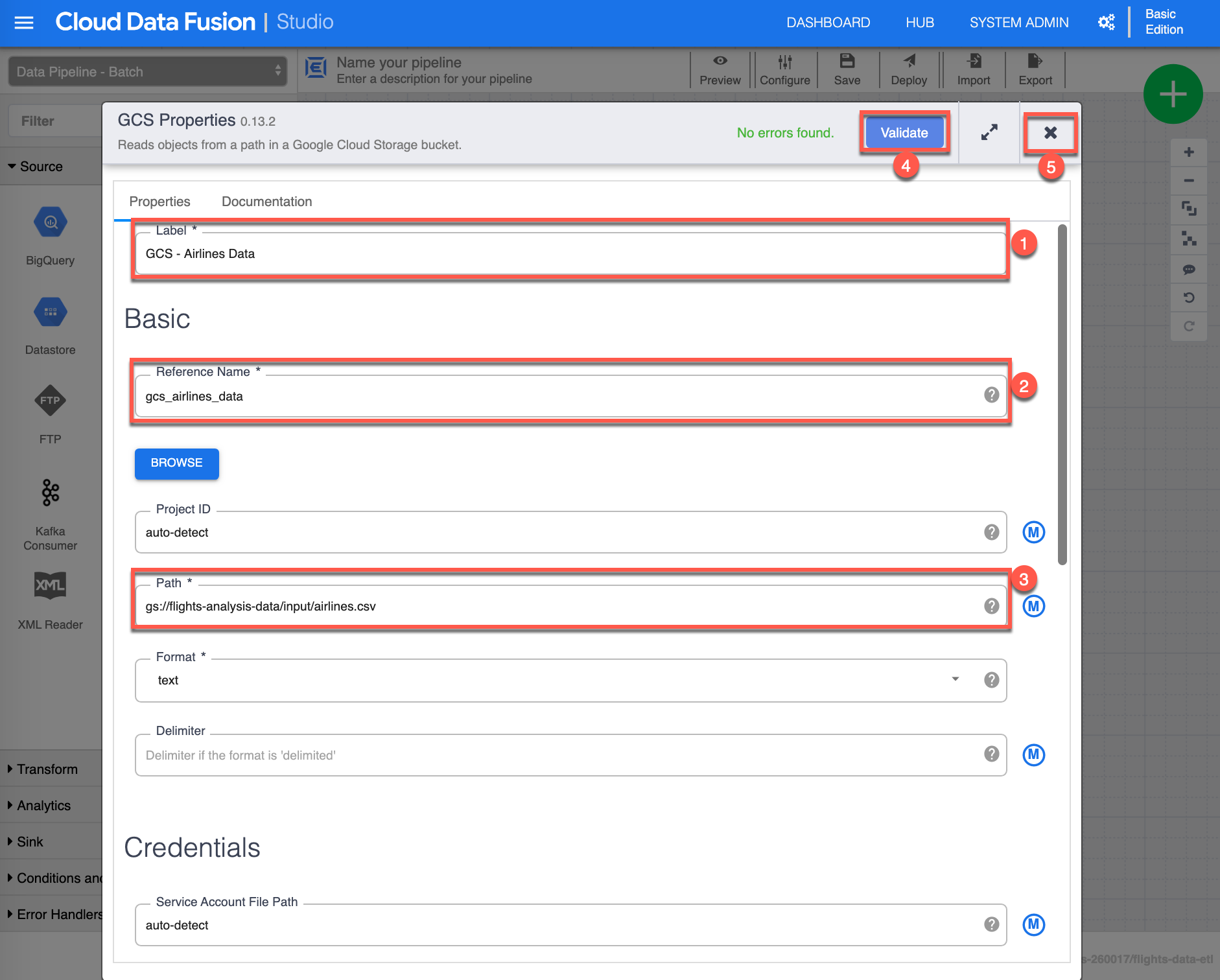
-
Like you did earlier on the flights_small.csv dataset, you now need to Wrangle the airlines.csv dataset, select or make sure you are in Transform (1) view, click the Wrangler (2) transform - this will add another Wrangler transform on the canvas, then Connect (3) by choosing and dragging the small arrow from the GCS - Airlines Data source to the newly created Wrangler transform and click Properties (4) from the Wrangler transform to continue.
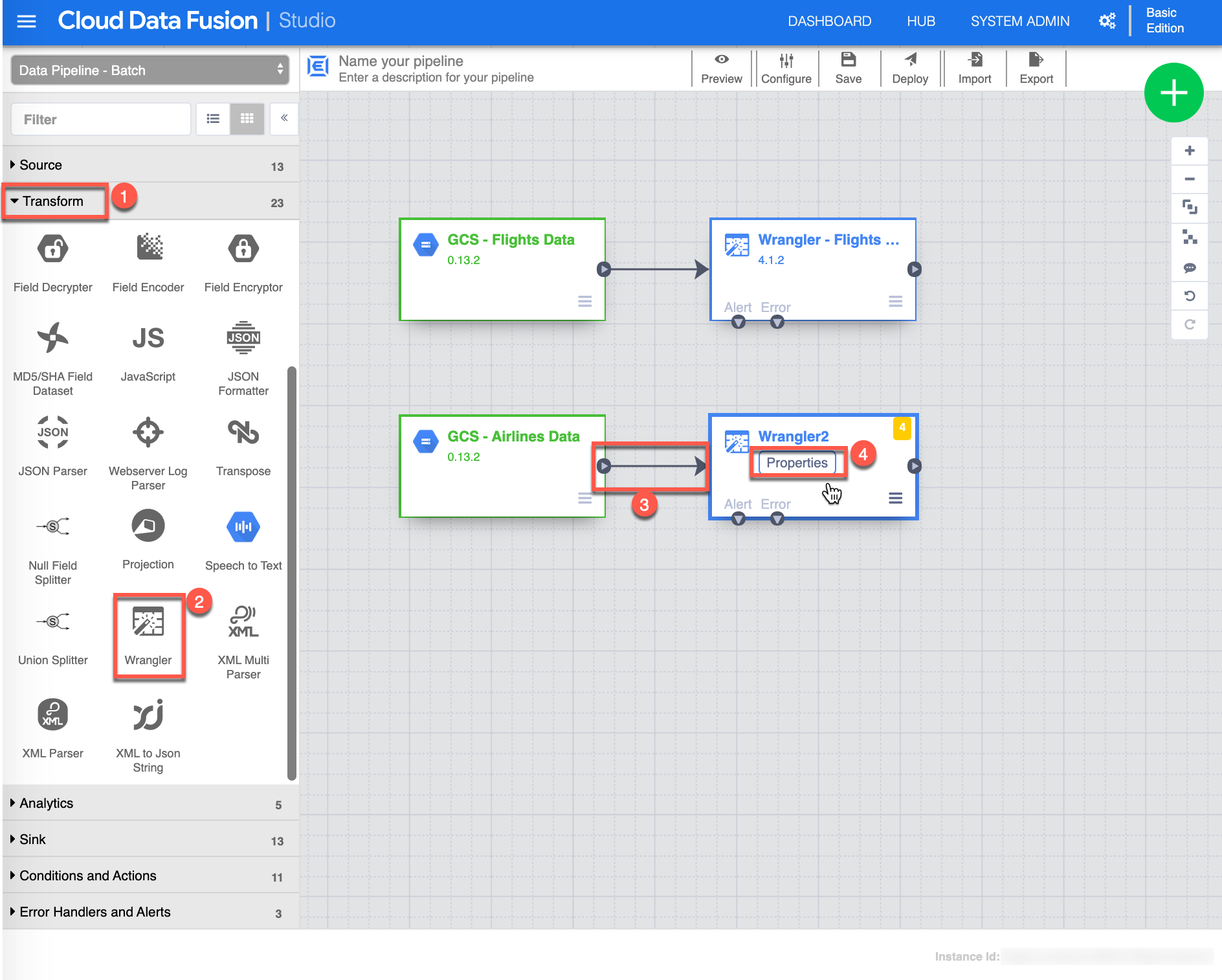
-
The Wrangler Properties configuration page shows up. Assign the following value for Label (1): “Wrangler - Airlines Data”, then click Wrangle (2) to continue.
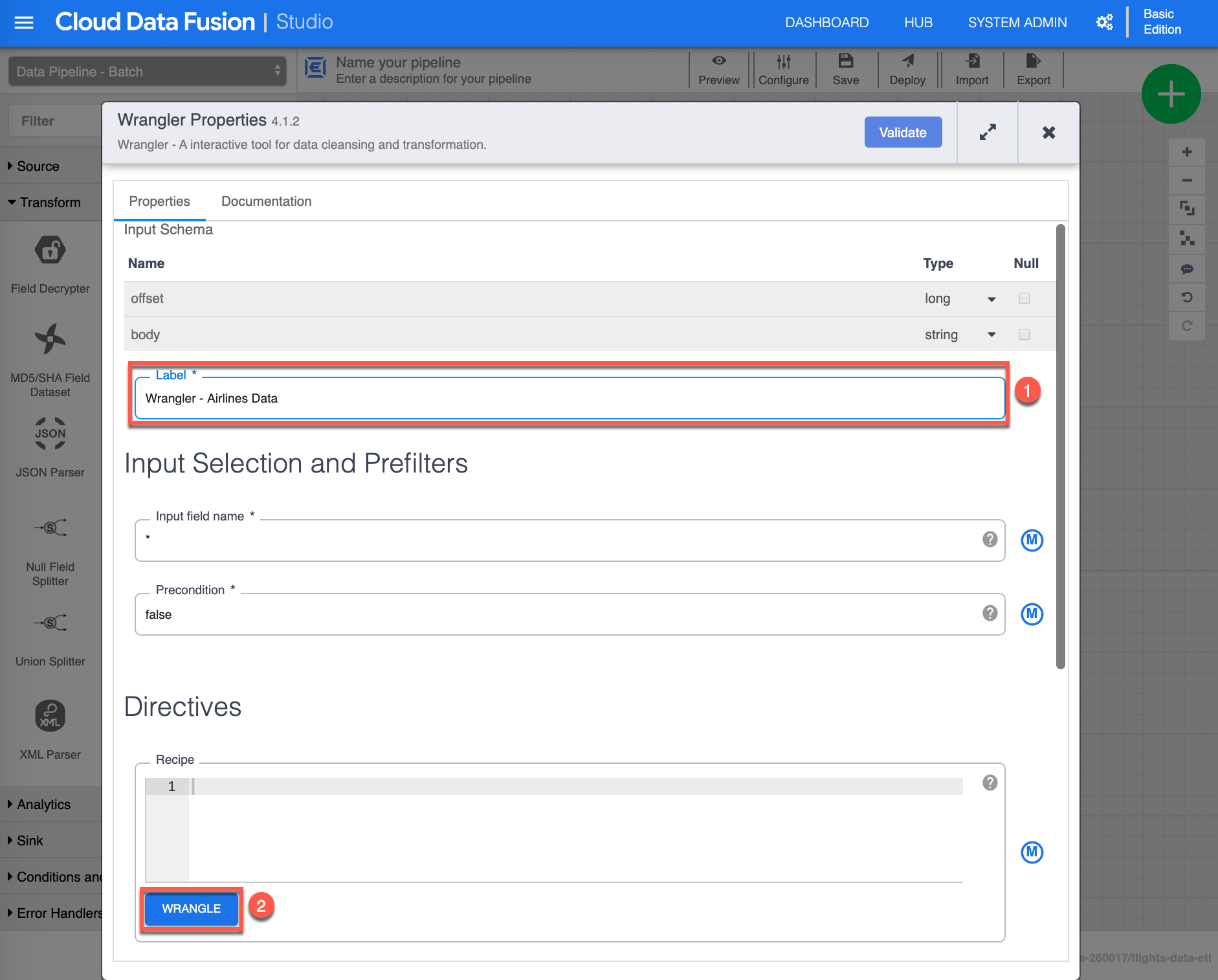
-
Like you did earlier you need to select/load data, choose the airlines.csv file that is located in your GCS bucket to continue.
-
Next are a series of steps to parse and remove unwanted columns. Click the dropdown [Column transformations] on the body (1) column, select Parse -> CSV (2), select Comma (3) as the delimiter, check Set first row as header (4), then click Apply (5) to continue.
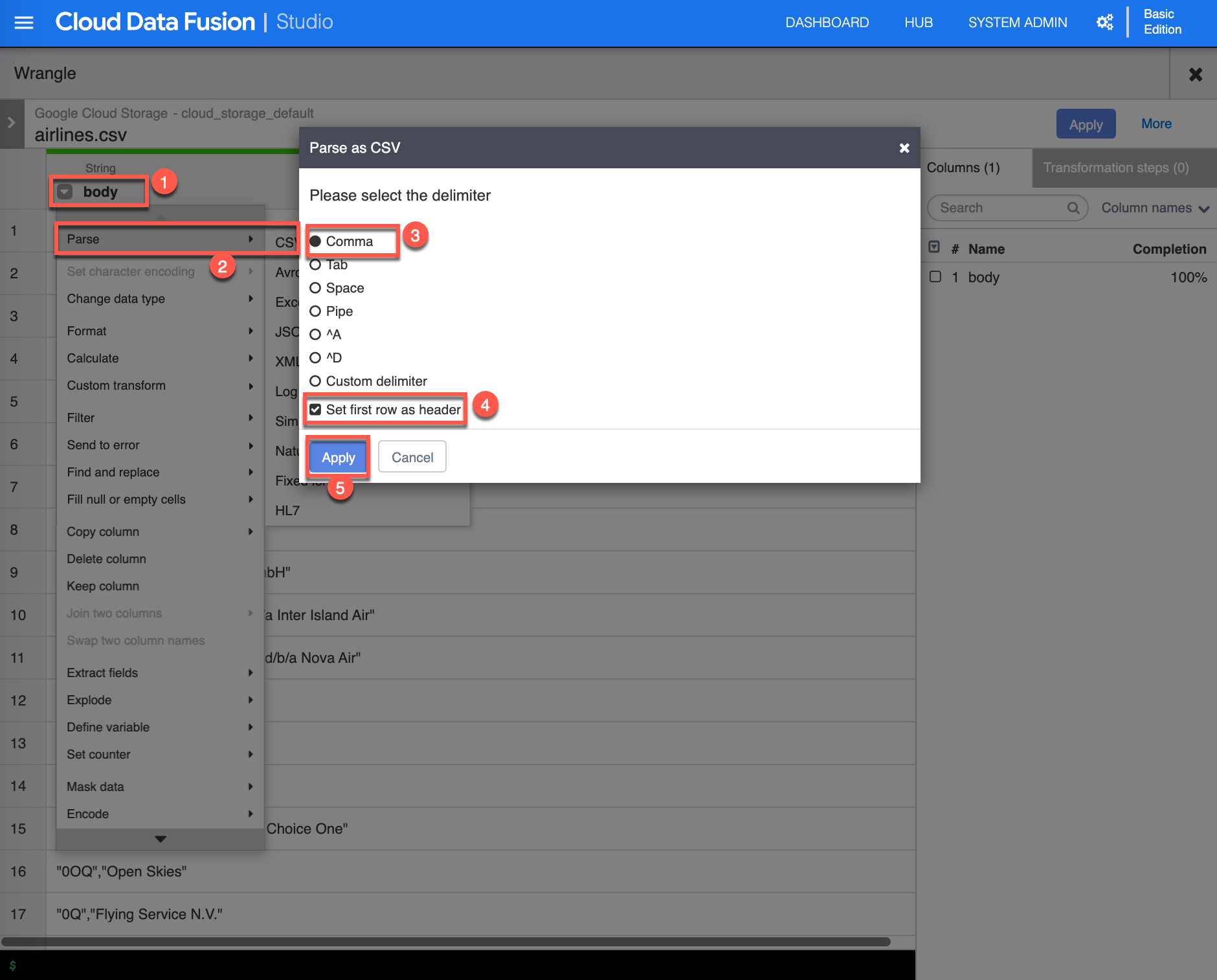
-
The result of the parse column transform added new columns and we want to remove the body column. Click the dropdown [Column transformations] on the body (1) column, then select Delete column (2), once completed click Apply (3) to continue.
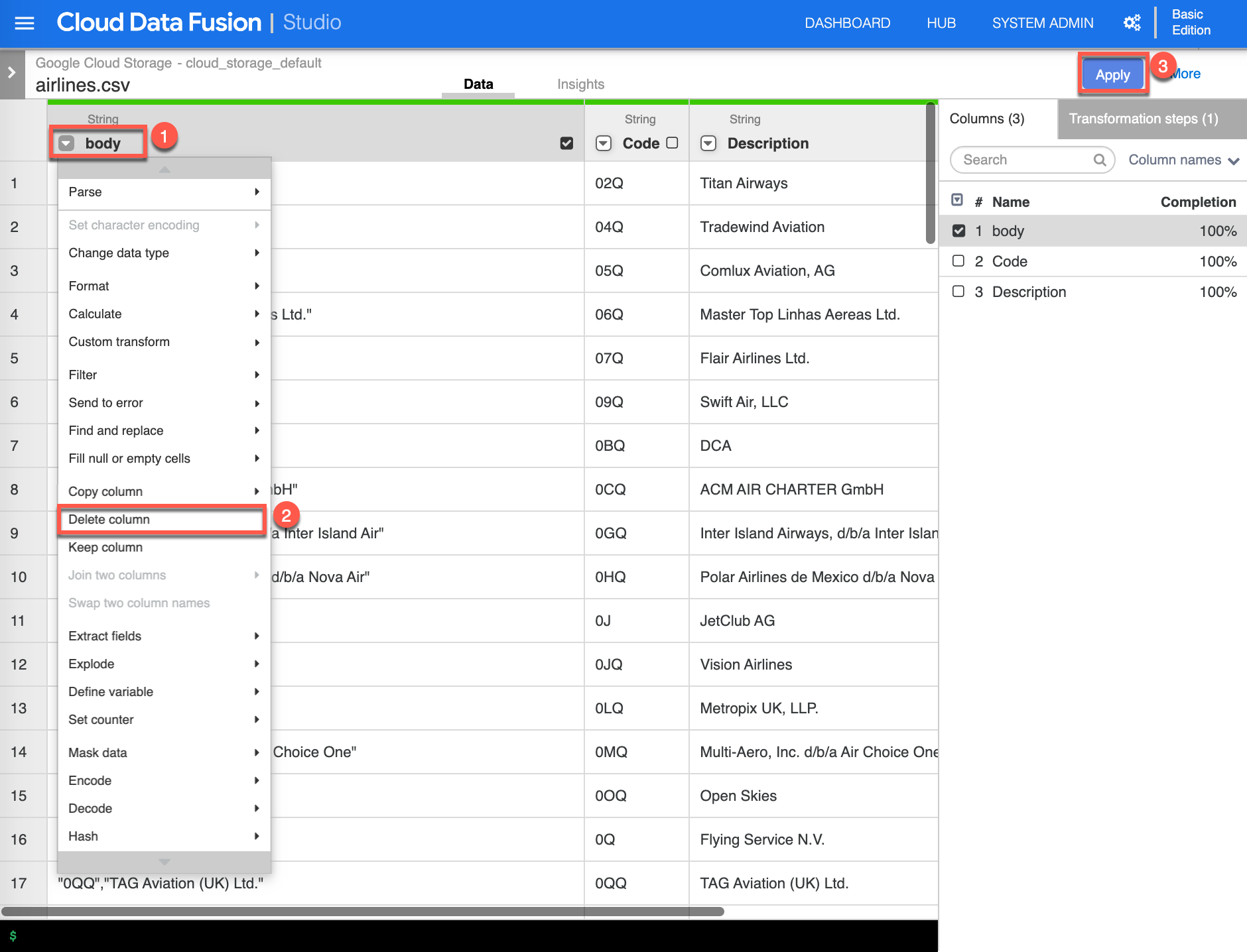
-
Again you will now notice that the Recipe box as been populated with the directives you just did in the Wrangling activities. Click Validate (1) to validate all properties, you should see in green No errors found, finally click X (2) to close/save the Wrangler properties.
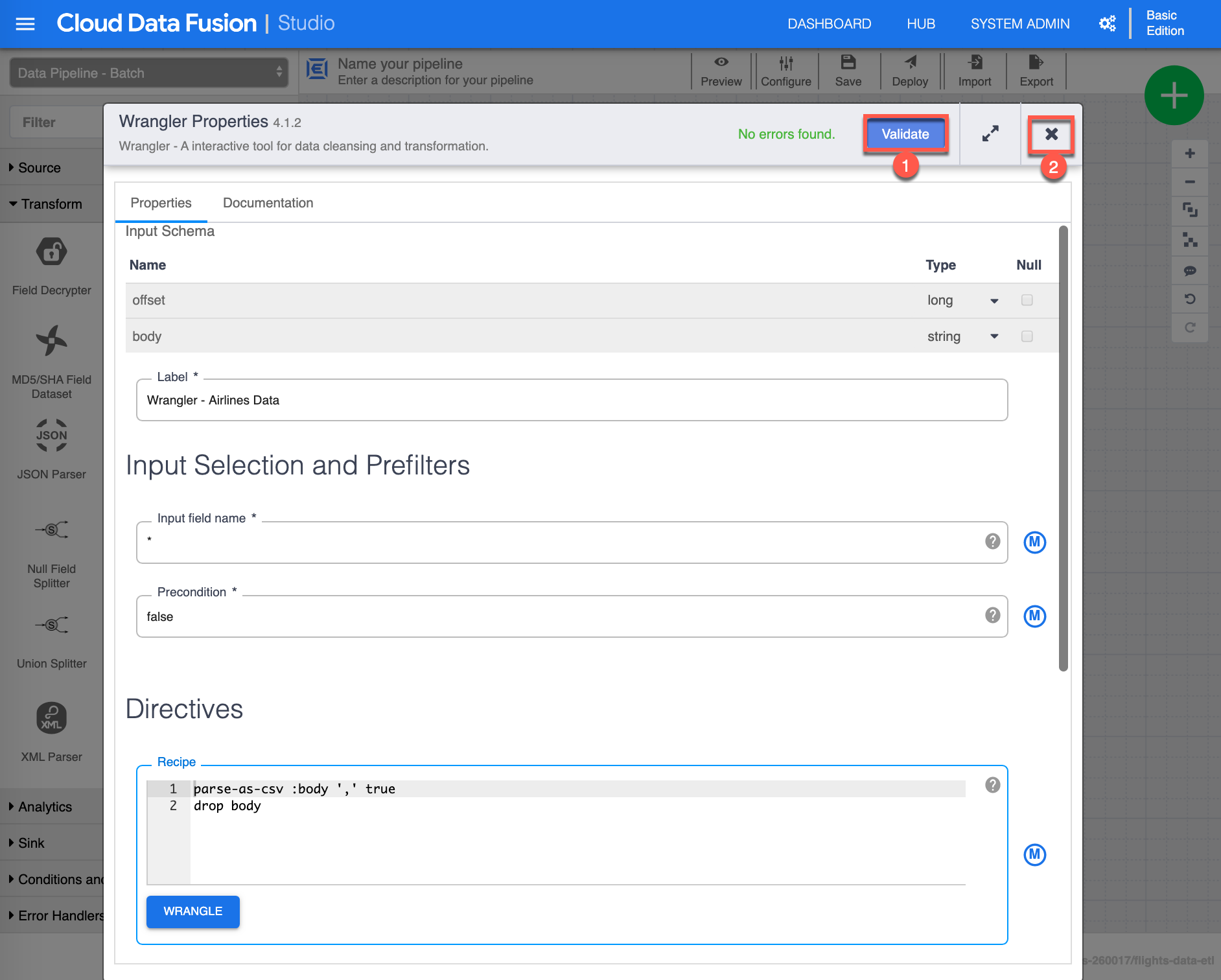
-
You are now ready to Join the two datasets. Start by selecting or make sure you are in Analytics (1) view , click Joiner (2) - this will add a Joiner task on the canvas, then Connect (3) by choosing and dragging the small arrow from the Wrangler - Flights Data to the Joiner and do the same for the Wrangler - Airlines Data, click Properties (4) from the Joiner task to continue.
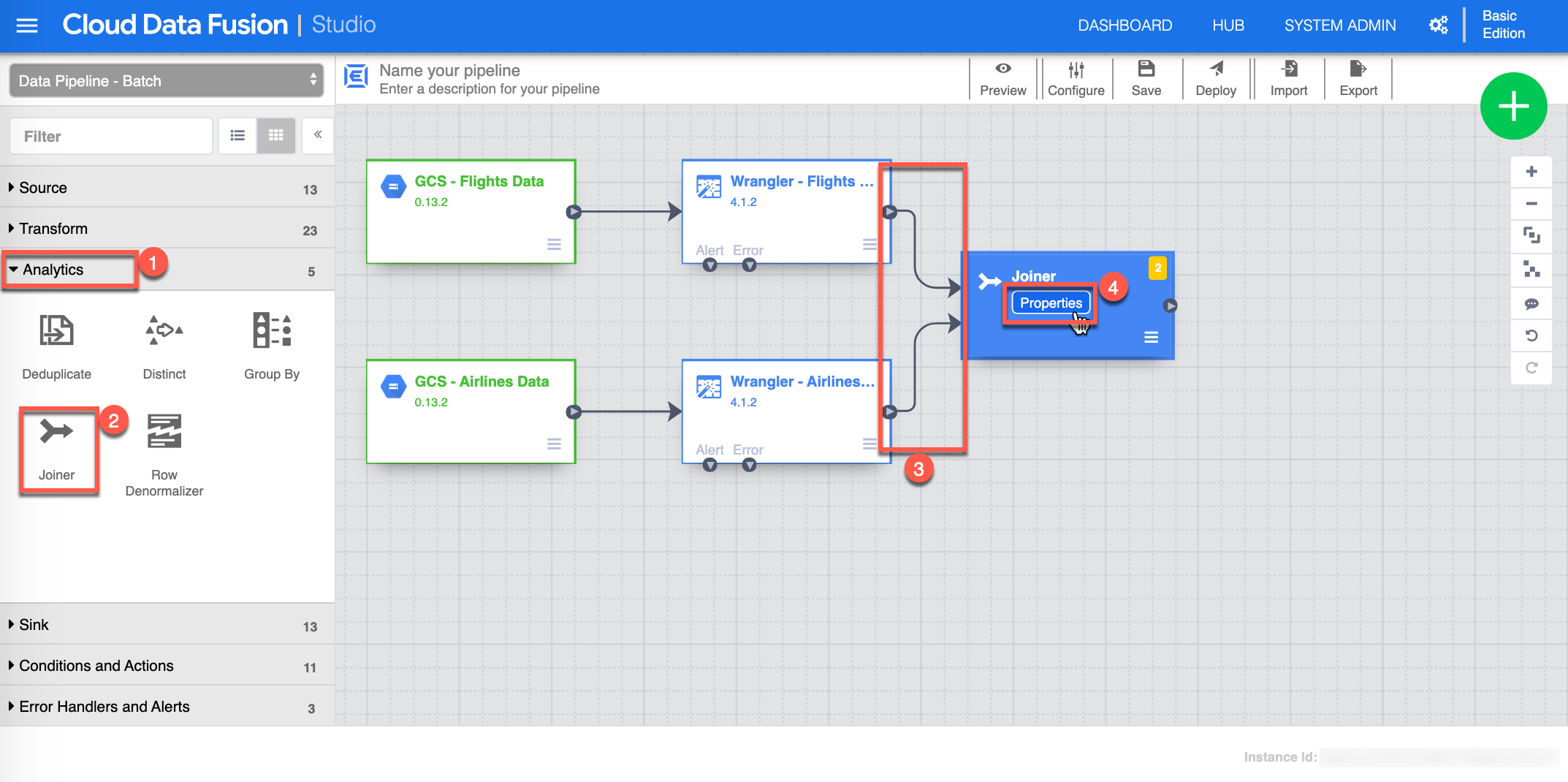
-
The Joiner Properties configuration box shows up. In the Join - Fields section, expand the Wrangler - Airlines Data (1) and uncheck Code (2) and assign the following value “Airline_name” to the Description Alias (3), select Inner (4) for the Join Type, in the Join Condition (5) section select the value “Airline” for Wrangler - Flight Data, and “Code” for Wrangler - Airlines Data, click Get (6) for the schema, then click Validate (7) to validate all properties, you should see in green No errors found, finally click X (8) to close/save the Joiner properties.
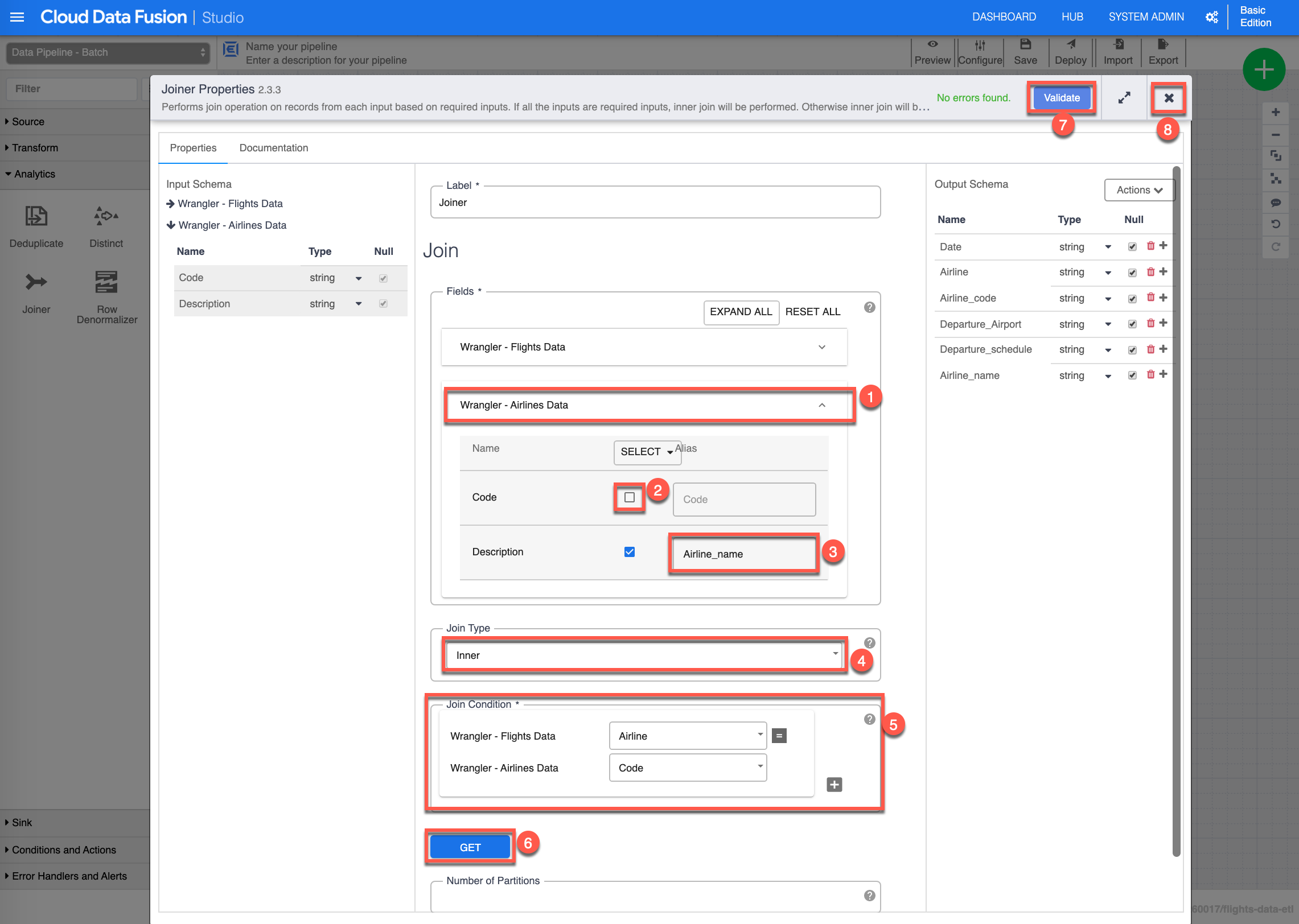
-
Next you need to Group By, and aggregate. Start by selecting or make sure you are in Analytics (1) view , click Group By (2) - this will add a Group By task on the canvas, then Connect (3) by choosing and dragging the small arrow from the Joiner to the Group By task, click Properties (4) from the Group By task to continue.
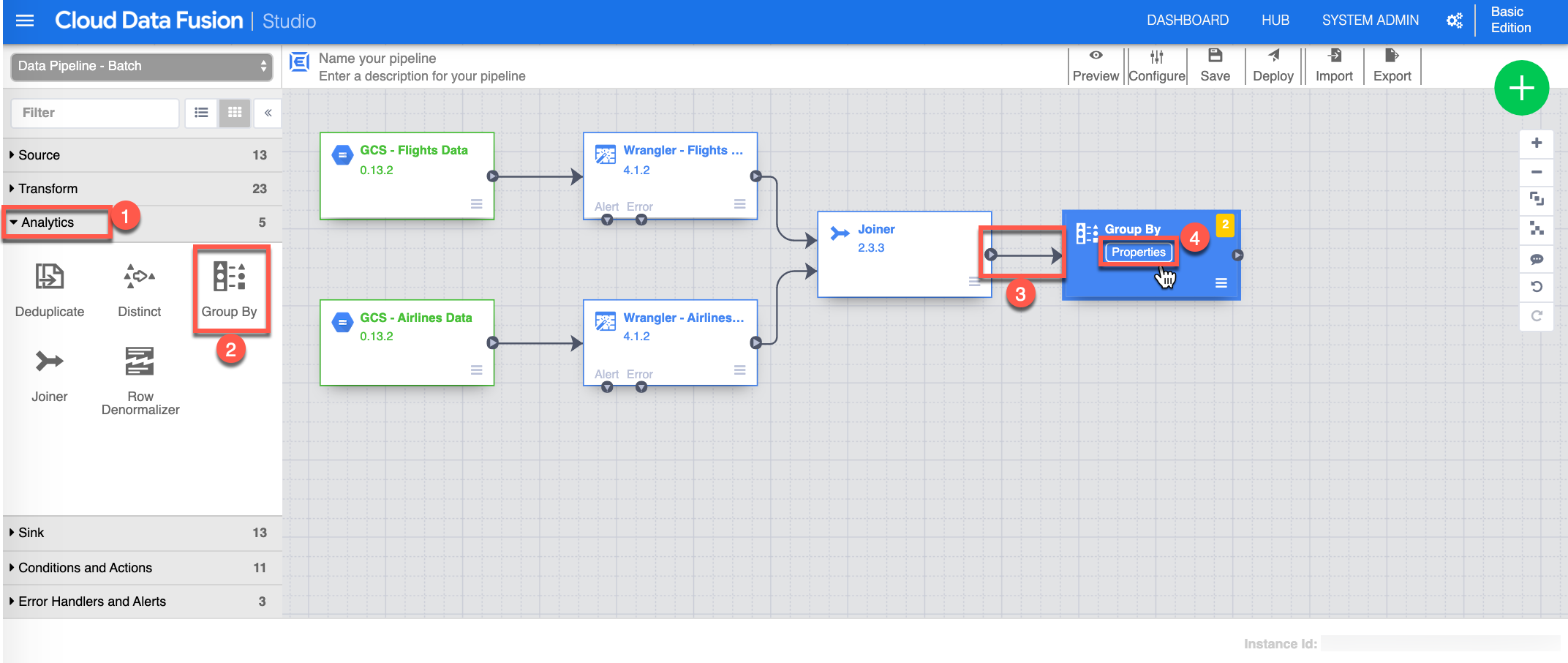
-
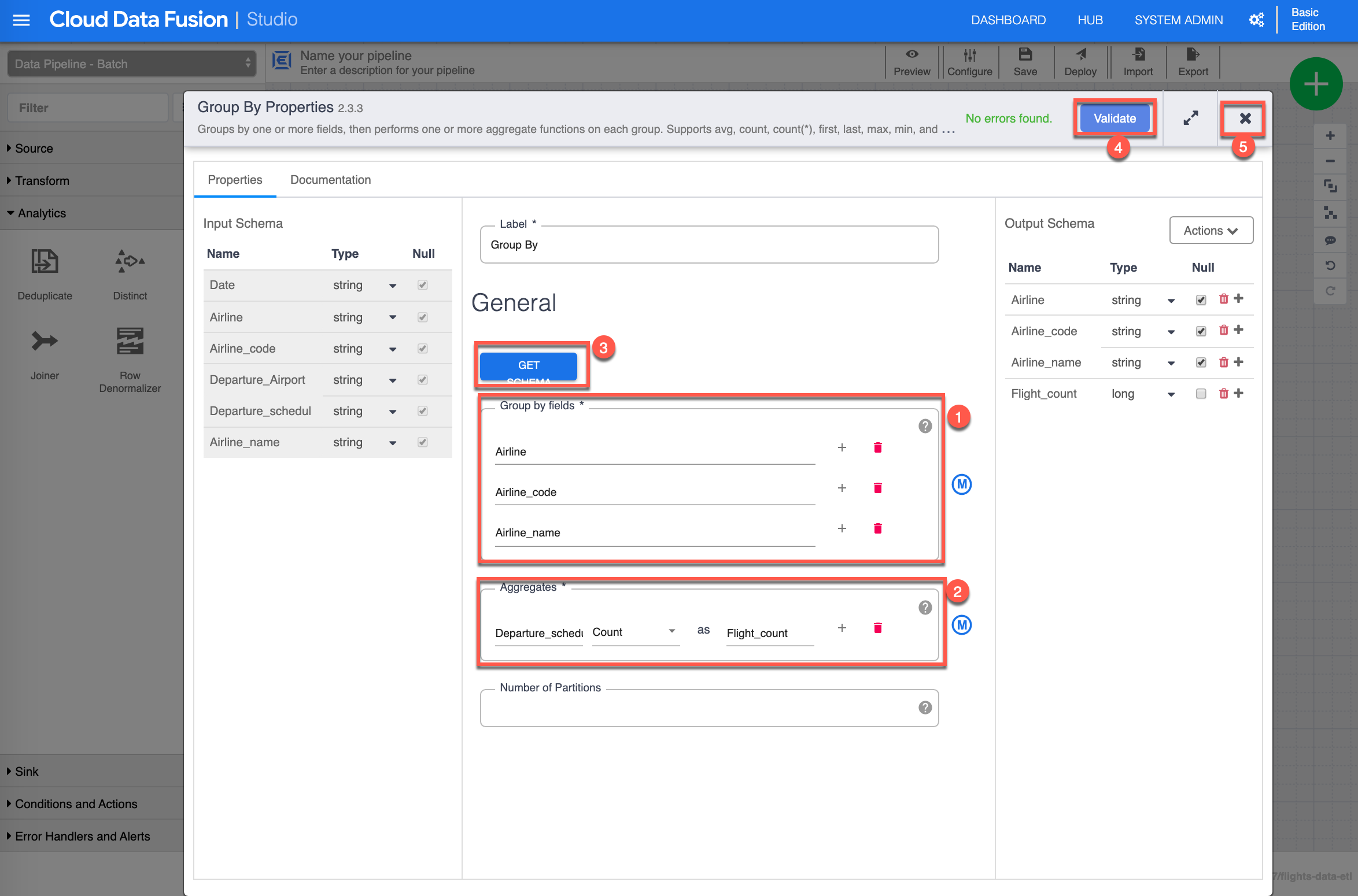
The Group By Properties configuration box shows up. In the Group by fields section (1) add the following fields: Airline, Airline_code, and Airline_name, in the Aggregates (2) section input “Departure_schedule”, select “Count” as the aggregation and input “Flight_count” as an alias, click Get Schema (3), then click Validate (4) to validate all properties, you should see in green No errors found, finally click X (5) to close/save the Group By properties.
-
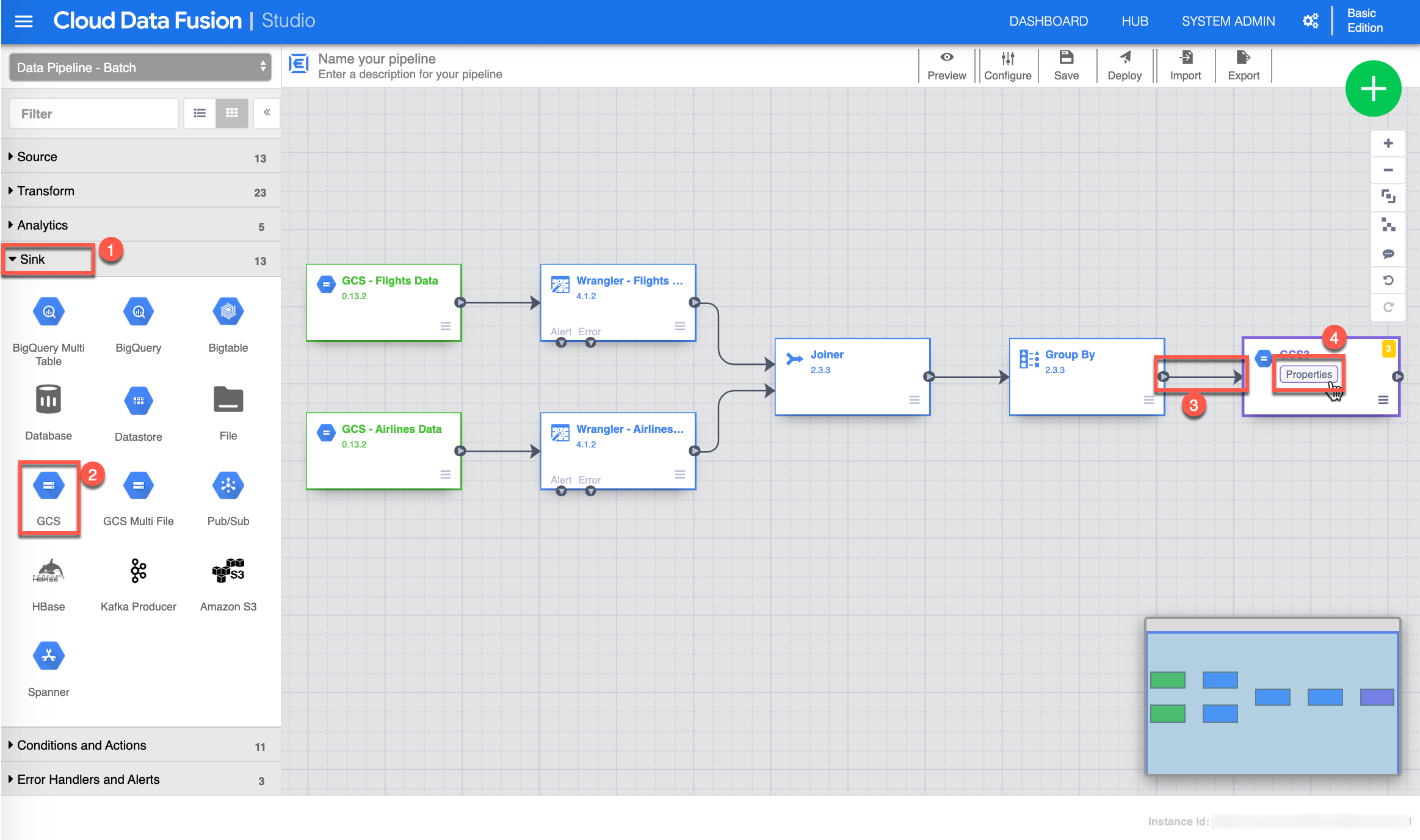
Finally to complete your data pipeline you need to set up a Sink to output the results. Start by selecting or make sure you are in Sink (1) view , click GCS (2) - this will add a GCS Sink on the canvas, then Connect (3) by choosing and dragging the small arrow from the Group By task to the GCS Sink, click Properties (4) from the GCS Sink to continue.
-
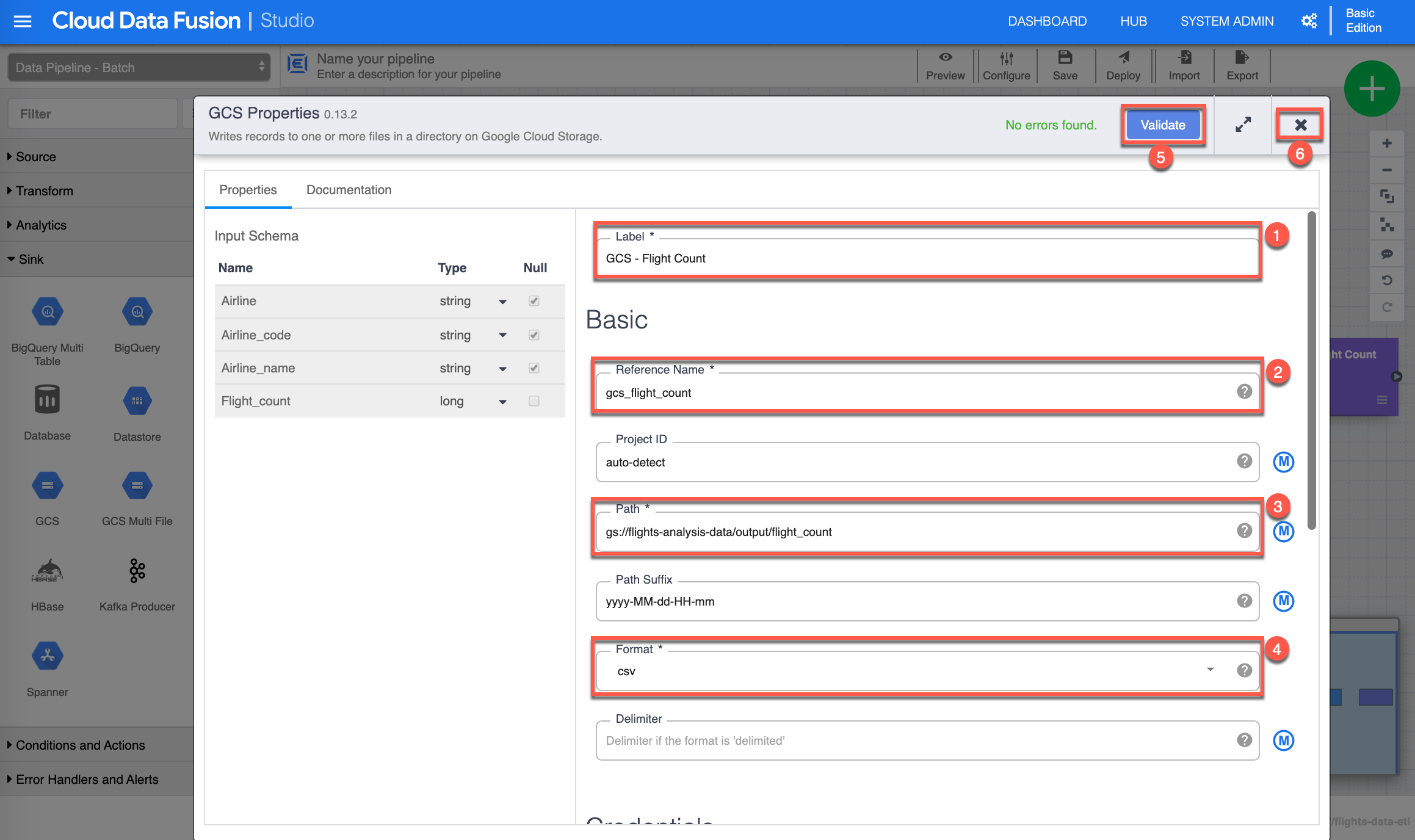
The GCS Properties configuration page shows up. Assign the following value for Label (1): “GCS - Flight Count”, then input the following value for Reference Name (2): “gcs_flight_count”, provide the Path (3) to the GCS Bucket for output you have created earlier. For the purpose of this exercise I have include mine, make sure to supply your appropriate path (if you input what is provided in this image, the validation won’t succeed), select “csv” for the Format (4) of the output file, click Validate (5) to validate all properties, you should see in green No errors found, finally click X (6) to close/save the GSC properties.
-
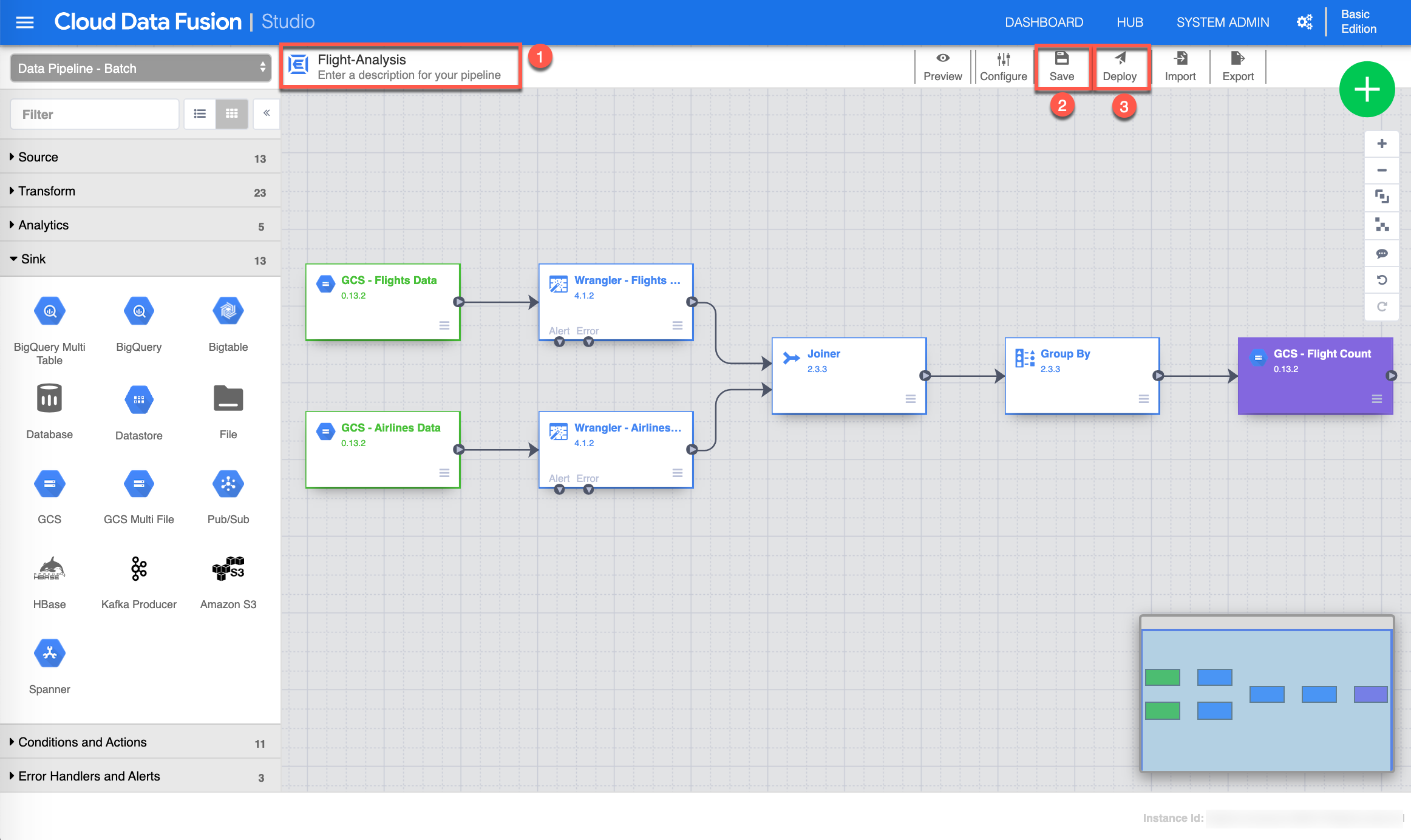
Congrats! You have completed building your data pipeline. Now give your pipeline a name (1), save (2) it and deploy (3) it. This will take a few moments to finalize and complete the deployment process.
-
You are now ready to execute your pipeline. Click Run.
-
The pipeline will go through different cycles; Deployed, Provisioning, Starting, Running, Deprovisioning and Succeeded indicated in the Status on the pipeline page. Once the pipeline Succeeded the next step is to go explore the output file in your GCS bucket.
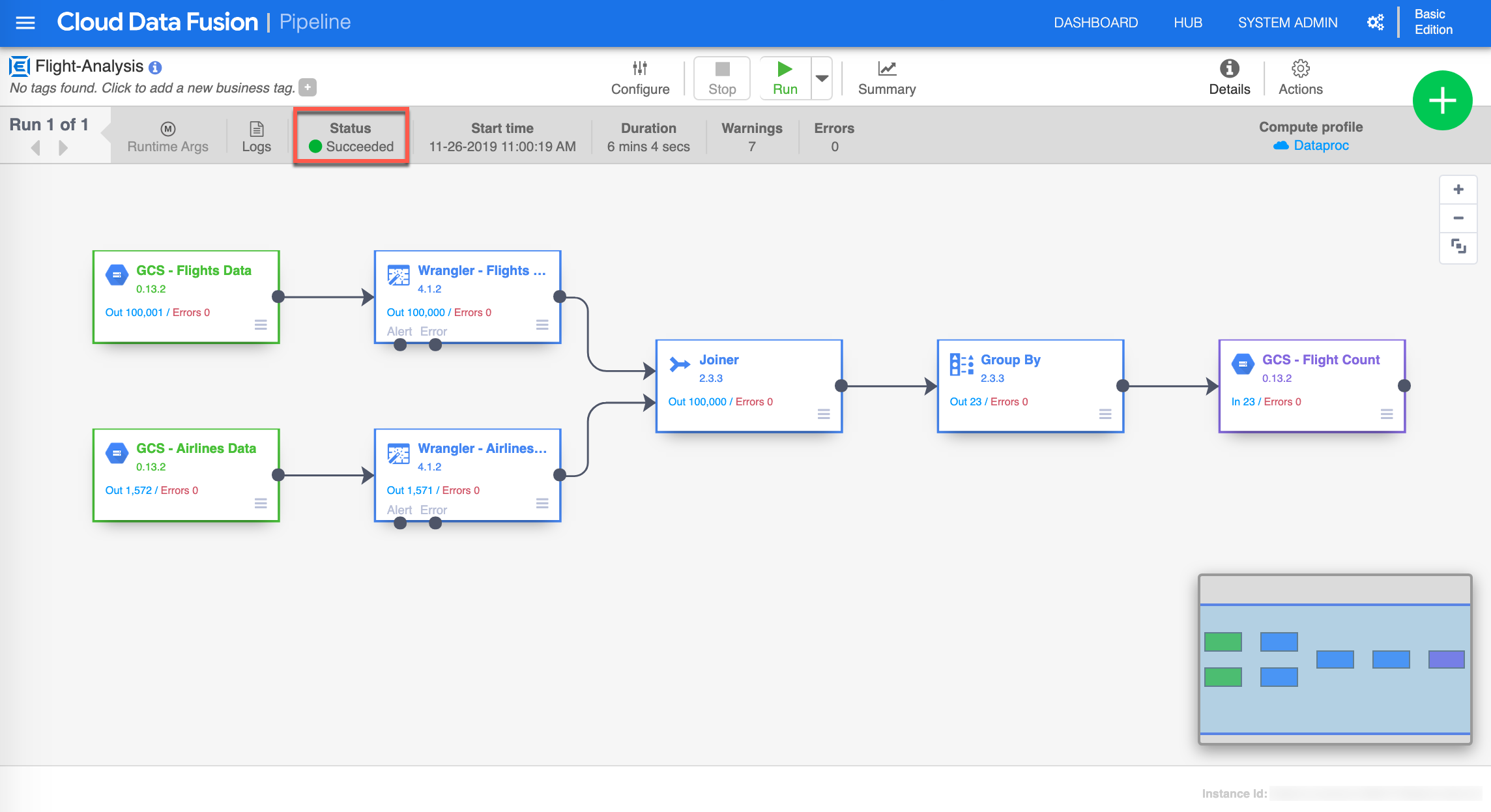
-
To validate the output sink of your pipeline, head over to your GCS bucket to the output folder and issue the following gsutil command to view the results. Make sure to replace [BUCKET_NAME] and [REPLACE_WITH_YOUR_FOLDER_DATE] with your information:
gsutil cat -h gs://[BUCKET_NAME]]/output/flight_count/[REPLACE_WITH_YOUR_FOLDER_DATE]/part-r-00000
The output is similar to the following:
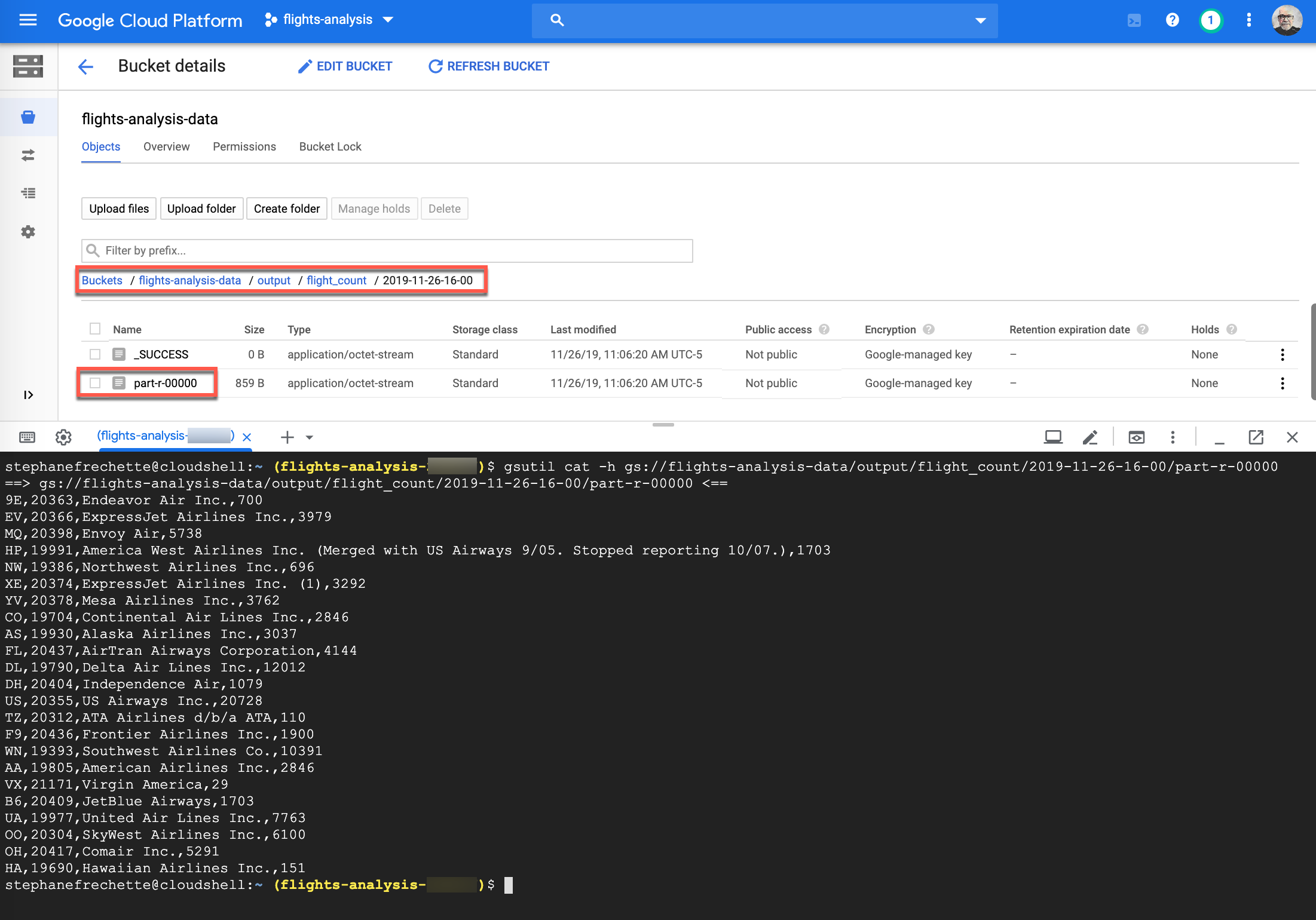
That’s it! You’ve just created and ran a complete data pipeline process on Cloud Data Fusion.
Cleanup Link to heading
To avoid incurring charges to your Google Cloud Platform account for the resources used in this walkthrough:
If you want to delete the entire project, follow these instructions:
- In the GCP Console, go to the Manage resources page.
- In the project list, select the project you want to delete and click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Or if you just want to delete your Cloud Data Fusion instance follow these instructions:
- To view your existing Cloud Data Fusion instances, open the Instances page.
- To select an instance, check the box next to the instance name.
- To delete the instance, click Delete.
Note: You can also delete an instance by clicking Delete on the instance details page.
Enjoy!