
You can view and download the data here from Google Drive. The code, sample queries and database backup can be found on Github.
Here is a sample from the Data sheet:
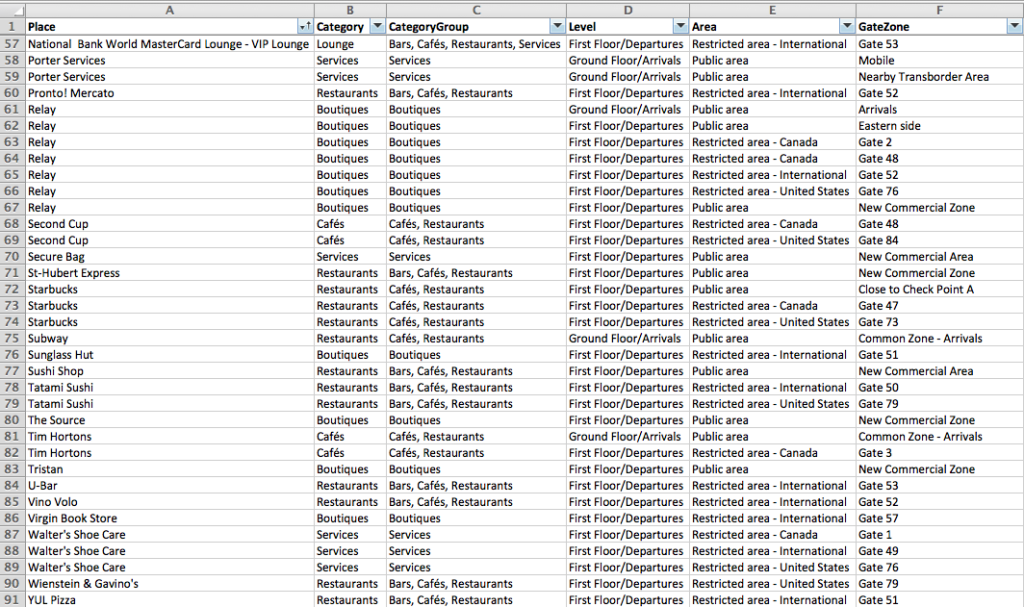
Essentially from the raw data collected I was able to create individual sheets for each ‘entities’ and for ‘relationships’, just like tables you would model in your favourite RDBMS and from that exported them to individual CSV files ready for import;
- area.csv
- categories.csv
- gatezones.csv
- levels.csv
- area.csv
- placecategorygatezone.csv
- places.csv
But first let take a look at how we will approach and model our graph, FYI at YUL airport there is no ‘Terminals’ but rather ‘Levels’…
Case in Point: A Place ‘Tim Hortons’ belongs in a Category ‘Cafés’ and that Place is located at a Gate ‘Gate 3’ in the following Area ‘Restricted area – Canada’ on a certain Level ‘First Floor/Departures’. Pretty straight forward and from that perspective we can create our model.
YUL Graph Model:

Importing the Data using Cypher
With the extracted CSV files will be using Cypher’s LOAD CSV command to transform and load the content into a graph structure.
You can import and run the entire Cypher script using the neo4j-shell by issuing the following command:
bin/neo4j-shell -path yul.db -file cypher/import.cypher
import.cypher
// Create indexes for faster lookup
CREATE INDEX ON :Category(categoryName);
CREATE INDEX ON :GateZone(gateZoneName);
CREATE INDEX ON :Area(areaName);
CREATE INDEX ON :Level(levelName);
// Create constraints
CREATE CONSTRAINT ON (a:Area) ASSERT a.areaId IS UNIQUE;
CREATE CONSTRAINT ON (c:Category) ASSERT c.categoryId IS UNIQUE;
CREATE CONSTRAINT ON (g:GateZone) ASSERT g.gateZoneId IS UNIQUE;
CREATE CONSTRAINT ON (l:Level) ASSERT l.levelId IS UNIQUE;
CREATE CONSTRAINT ON (p:Place) ASSERT p.placeId IS UNIQUE;
// Create places
USING PERIODIC COMMIT
LOAD CSV WITH HEADERS FROM "file:data/places.csv" as row
CREATE (:Place {placeName: row.PlaceName, placeId: row.PlaceID});
// Create categories
USING PERIODIC COMMIT
LOAD CSV WITH HEADERS FROM "file:data/categories.csv" as row
CREATE (:Category {categoryName: row.CategoryName, categoryId: row.CategoryID});
// Create gatezones
USING PERIODIC COMMIT
LOAD CSV WITH HEADERS FROM "file:data/gatezones.csv" as row
CREATE (:GateZone {gateZoneName: row.GateZoneName, gateZoneId: row.GateZoneID});
// Create levels
USING PERIODIC COMMIT
LOAD CSV WITH HEADERS FROM "file:data/levels.csv" as row
CREATE (:Level {levelName: row.LevelName, levelId: row.LevelID});
// Create areas
USING PERIODIC COMMIT
LOAD CSV WITH HEADERS FROM "file:data/areas.csv" as row
CREATE (:Area {areaName: row.AreaName, areaId: row.AreaID});
// Create relationships: Place to Category
USING PERIODIC COMMIT
LOAD CSV WITH HEADERS FROM "file:data/placecategorygatezone.csv" AS row
MATCH (place:Place {placeId: row.PlaceID})
MATCH (category:Category {categoryId: row.CategoryID})
MERGE (place)-[:IN_CATEGORY]->(category);
// Create relationships: Place to GateZone
USING PERIODIC COMMIT
LOAD CSV WITH HEADERS FROM "file:data/placecategorygatezone.csv" AS row
MATCH (place:Place {placeId: row.PlaceID})
MATCH (gatezone:GateZone {gateZoneId: row.GateZoneID})
MERGE (place)-[:AT_GATEZONE]->(gatezone);
// Create relationships: GateZone to Area
USING PERIODIC COMMIT
LOAD CSV WITH HEADERS FROM "file:data/gatezones.csv" AS row
MATCH (gatezone:GateZone {gateZoneId: row.GateZoneID})
MATCH (area:Area {areaId: row.AreaID})
MERGE (gatezone)-[:IN_AREA]->(area);
// Create relationships: Area to Level
USING PERIODIC COMMIT
LOAD CSV WITH HEADERS FROM "file:data/areas.csv" AS row
MATCH (area:Area {areaId: row.AreaID})
MATCH (level:Level {levelId: row.LevelID})
MERGE (area)-[:AT_LEVEL]->(level);
Start Neo4j and load the web console (http://localhost:7474), we are now ready to issue some Cypher queries…
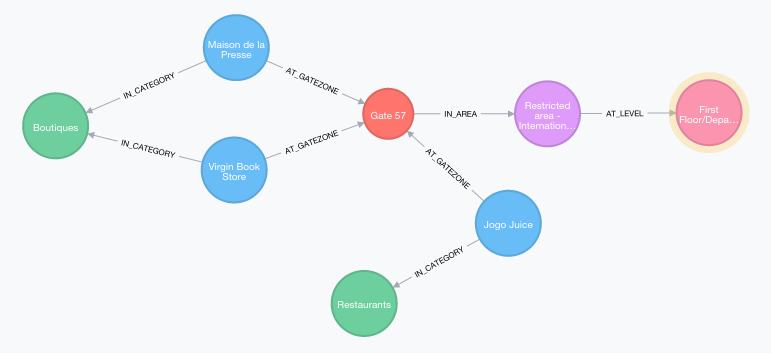
Find all places and their categories located at Gate 57 (with Area and Level)
MATCH (c:Category)<--(p:Place)-->(g:GateZone)-->(a:Area)-->(l:Level)
WHERE g.gateZoneName = 'Gate 57'
RETURN c, p, g, a, l;
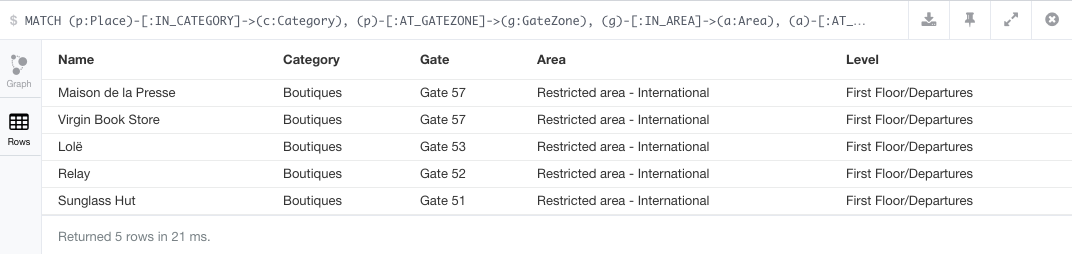
Find Boutiques in Restricted area – International on First Floor/Departures
MATCH (p:Place)-[:IN_CATEGORY]->(c:Category),
(p)-[:AT_GATEZONE]->(g:GateZone),
(g)-[:IN_AREA]->(a:Area),
(a)-[:AT_LEVEL]->(l:Level)
WHERE c.categoryName = 'Boutiques' AND a.areaName = 'Restricted area - International' AND l.levelName = 'First Floor/Departures'
RETURN p.placeName AS Name, c.categoryName AS Category, g.gateZoneName AS Gate, a.areaName AS Area, l.levelName AS Level
Return count of places in each Category
MATCH (p:Place)-[:IN_CATEGORY]-(c:Category)
RETURN c.categoryName AS Category, collect(distinct p.placeName) as Place, count(p) AS Count
ORDER BY Count DESC

Take time to explore the data and try to write your own queries!
Don’t forget the available online training from Neo4j: Getting Started with Neo4j and recently added Neo4j in Production http://neo4j.com/graphacademy/online-training/